Why is it not possible for me to use the user.name field in the "by field" section of a machine learning job, but the standard jobs have no problem with it?
As you can see it is not an option for me:

But the standard jobs can use it somehow:
Because the UI wants to encourage you to use the user.name.keyword field (the keyword type of the field called user.name). This ensures that users do not make a mistake by choosing a field that isn't "aggregatable". Configuring the ML job through the API (or by enabling it via the Security App, which in turn uses the API) bypasses this safety check.
Based on your other recent questions, it seems like you do not understand the concepts of mappings, data types, and how that data is manifested in the index. May I suggest that you understand those concepts first?
Im definitely going to explore that at a later point. Unfortunately, im currently working on this for a school project and am very bound by the time i have. Could you maybe point me in the direction of an explanation on how to turn off this feature using the security app?
Again, based on what you're saying on other threads, you just need to configure ML to use the fields that are actually in the data but also recognize that if you're using the UI, the UI will suggest you use the .keyword version of the field and that will be fine.
If you insist on using the non-keyword version of the field (i.e. user.name and not user.name.keyword then you cannot use the ML job wizards - you must use the API. But this is a futile exercise. Just use the .keyword version of the field.
The keyword function does not work though.
You'll need to be more specific. What doesn't work? Being able to select it via the UI? The job won't run? You don't get results?
It does not get results
Have you considered that it is possible that there are actually no anomalous examples in the data set you are using? In other words, let's say you're attempting to find a rare user name, but all of the user names in the data are consistent or routine. If that's the case, there will be no anomalies found and you will not get any "results".
Here's an older (but still relevant) article that discusses some of the nuances around rarity analysis.
Yes I have most definitely considered that. But quickly rejected that idea. Because that does not make sense since the standard job does get results.
Ok, maybe I've lost your intent given the flurry of messages across your several separate posts/threads on this discussion forum.
So, let's back up - what are you actually trying to accomplish and why isn't using the "standard job" adequate?
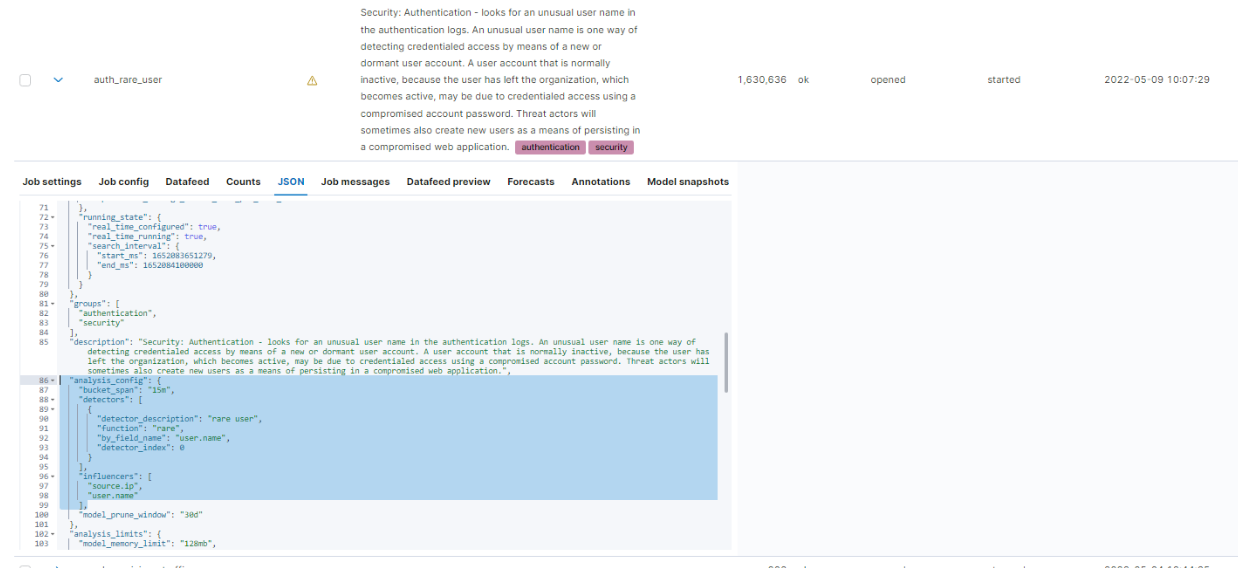
I am trying to set up a custom machine learning job that allows me to use user.name as the "by field" value for a job that recognizes anomalous users in powershell execution. I have saved a search query that filters all winlogbeat data and only shows the logs that say powershell was started. With this data i want to set up a machine learning job to detect rare user names to find anomalous occurences.
However, I cannot use the field user.name as the "by field" value. And when using the value user.name.keyword no user names get shown in the data preview. I verified the problem is not the data. So, how can i use the user.name field like in the example ml jobs in order to make my job work.
Show me the datafeed preview output where user.name.keyword is used and also where user.name is used.
Also, I'd be curious to see your entire datafeed configuration.
When using user.name.keyword:
[
{
"@timestamp": 1650963592372
},
{
"@timestamp": 1650963592372
},
{
"@timestamp": 1651475677937
},
{
"@timestamp": 1651477991283
},
{
"@timestamp": 1651477991283
},
{
"@timestamp": 1651478109665
},
{
"@timestamp": 1651478109665
},
etc...
When using user.name:
[
{
"@timestamp": 1650963592372,
"user.name": "flindenburg"
},
{
"@timestamp": 1650963592372,
"user.name": "flindenburg"
},
{
"@timestamp": 1651475677937,
"user.name": "msijstermans"
},
{
"@timestamp": 1651477991283,
"user.name": "avriel"
},
{
"@timestamp": 1651477991283,
"user.name": "avriel"
},
etc...
So user.name gets results and user.name.test does not. So, why is it that kibana does not show user.name as an option:
Nor does it let me add it manually because its automatically deleted.
Thanks for the info, please also provide the output of the following:
GET metricbeat-*/_mapping
This is the output:
{ }
I am using winlogbeat though
My bad I meant:
GET winlogbeat-*/_mapping
There seems to be too much content to post it. Is there a specific part that you are looking for that I can search for and upload here?
put it in a google doc, a pastebin or a gist, or whatever and link here.
I hope you can reach it like this:
https://drive.google.com/file/d/1OQ2PZVp8PoGYLkBxpkFFXL2lPd4_dJoC/view?usp=sharing
That's good thanks - one more thing...please send the output of:
GET winlogbeat-*/_field_caps?fields=user*
© 2020. All Rights Reserved - Elasticsearch
Apache, Apache Lucene, Apache Hadoop, Hadoop, HDFS and the yellow elephant logo are trademarks of the Apache Software Foundation in the United States and/or other countries.