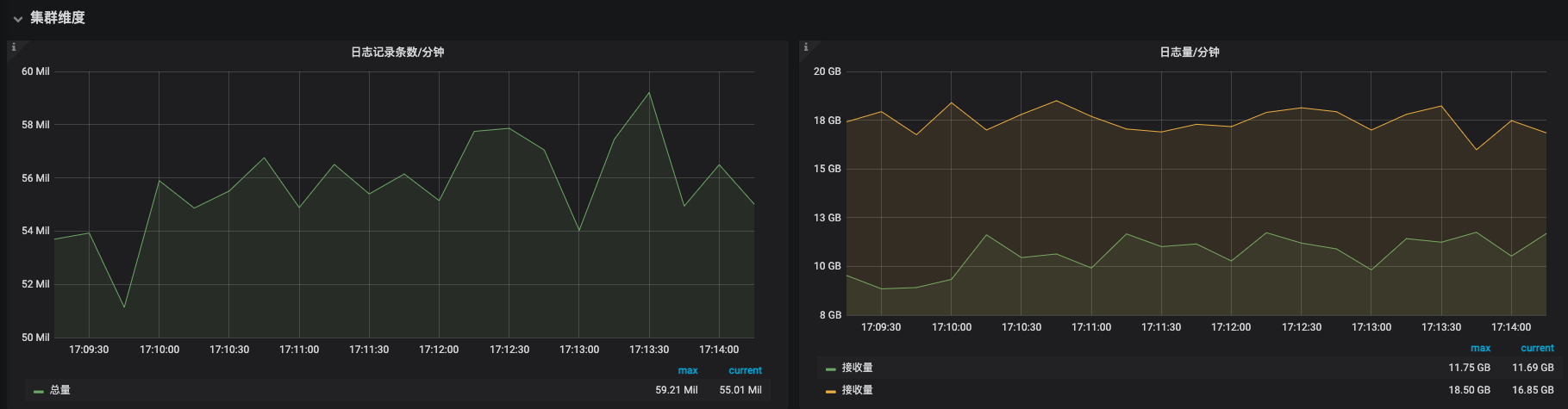
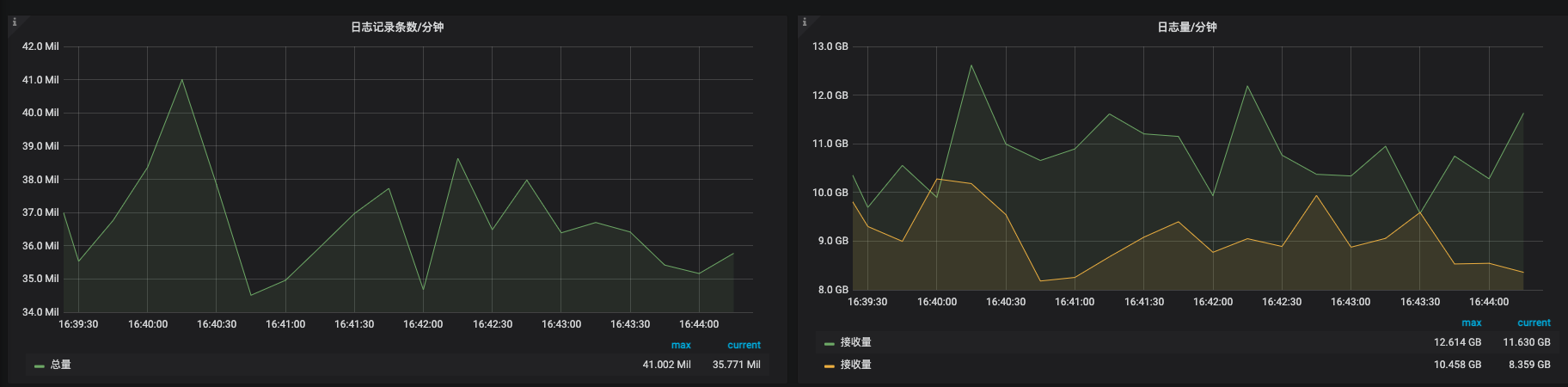
I am now testing the write performance of ES(v7.13.4), the number of shards written is constant, I added many empty indexes(shard number is 3). Then I find that the write performance is degraded even if the index is closed. Indices metadata and routing table are all map structures, this does not affect. Please tell me what caused it.
The test results are as follows:
Index number: 5790
Total shard number: 7974
Open shard: 7974
In recent versions Elasticsearch is keeping track of closed indices, so I assume a large number of closed indices would increase the size of the cluster state more than before. I assume this could potentially slow down cluster state updates, if you create new indices as part of your indexing or use dynamic mappings which result in mapping updates to the cluster state.
Are you using dynamic mappings? What does indexing performance look like if you index data into a few existing indices in a static format that does not result in new mappings? Why do you have so many closed indices in your cluster in the first place?
Memory consumption related to shards have shrunk in recent version compared to e.g. Elasticsearch 5.x, so if resource usage is the reason you are closing indices this may no longer be required.
Creating lots of.small indices and shards are however quite inefficient. Why are you creating so many small indices s as no shards?
It sounds like you are using Elasticsearch in an unusual way that is not necessarily following best practices. If you could describe your use case the community might be able to find a better way for you to shard and manage your data.
If I recall correctly the change was introduces around the time when frozen indices were introduced. Before this closed indices were not at all monitored by the cluster and a node failure would not cause closed indices to get replicated to new nodes. For some use cases that relied on closed indices for handling very old data a couple of nodes failung could lead to the loss of all shard copies for specific shards, resulting in permanent data loss and red indices.. This is what I believe the change aimed at correcting.
Apache, Apache Lucene, Apache Hadoop, Hadoop, HDFS and the yellow elephant
logo are trademarks of the
Apache Software Foundation
in the United States and/or other countries.