I use average bucket to calculate tps.
First, Working case
aggregation: average bucket
bucket: date histogram, field: @timestamp, minimum interval: second
metric: count

this case, is ok.
inspect:


The calculation process looks like below......
- count per bucket
- calculate average count
3. average count / minimum interval: second(3h = 10800)
Second, Not Working case
aggregation: average bucket
bucket: date histogram, field: @timestamp, minimum interval: second
metric: unique count, field: primary key field
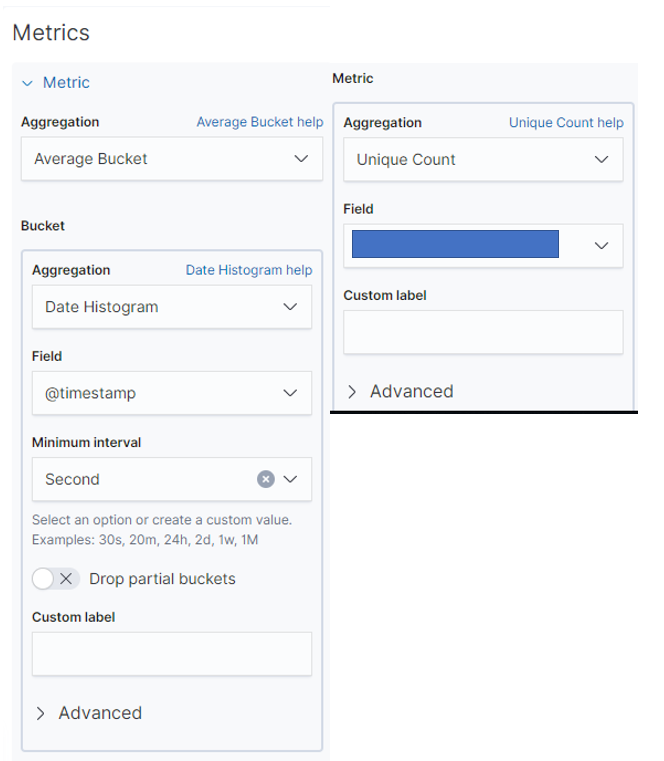
inspect:


The calculation process looks like below......
1.unique count per bucket
2. calculate average unique count
why don't calculate process 3???
(average unique count /minimum interval: second(3h = 10800)