I know this is probably a long shot but I wonder if it somehow is possible to calculate values like this.
Example:
Every day I'm ingesting a new value that is the total value of X for month to date. 01/02 might be 10, 02/02 might be 50, and 03/02 80 etc.
Looking at the data it is clear that the actual value for the 3rd would be 20 as the 1st and 2nd add up to 60.
Is it possible to have Kibana somehow perform such a calculation so it takes the value for day X, deducts the value for the previous day and then return the result as something that can be graphed?
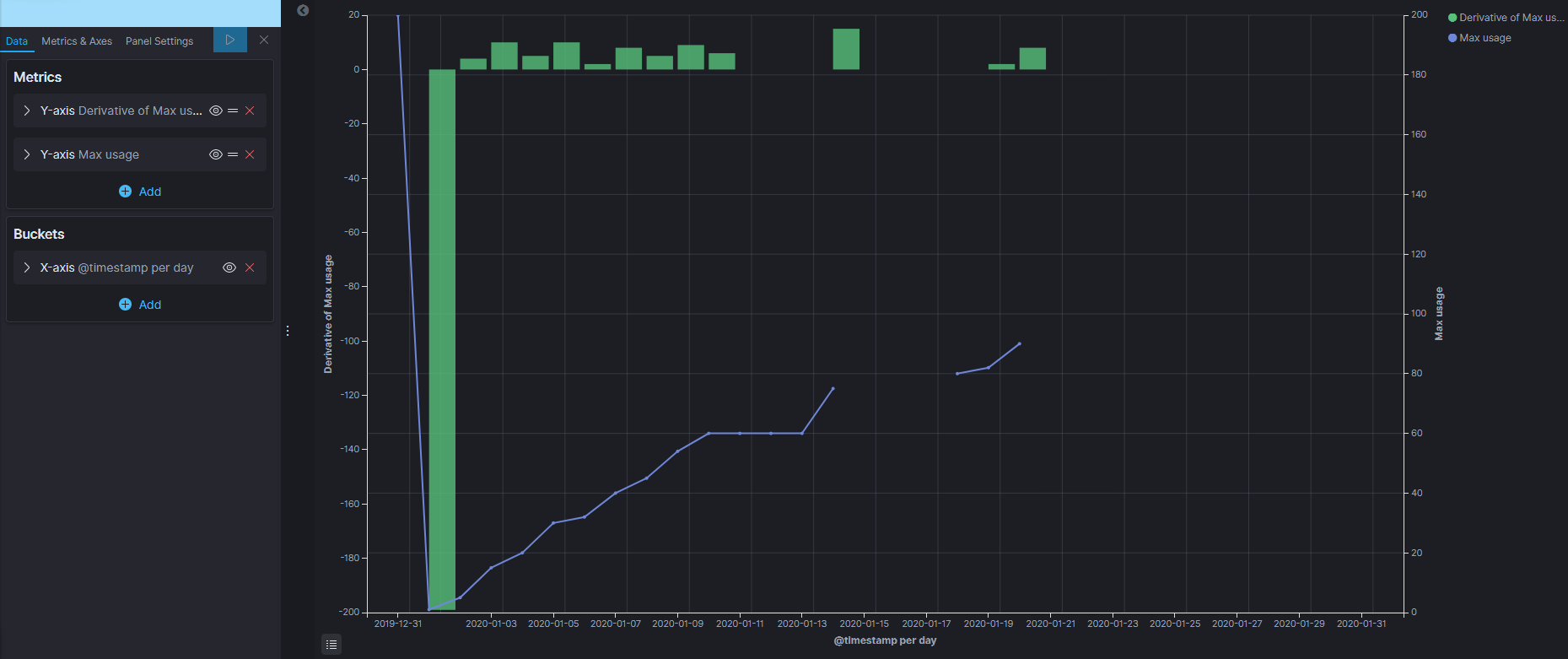
It sounds like the "Derivative" aggregation is doing what you want - it will give you the difference between the defined metric for the current bucket and the previous bucket:
If the value in your docs resets each month, you can split the series by a monthly date histogram to prevent having a huge negative spike on each first of the month (each month will have its own derivative series).
Thanks, that works almost perfectly. My data is daily so I have to pick daily instead of monthly. Monthly returns only 1 bar per month.
The only downside for me is that I indeed get a negative graph on the first of the month when the value resets and there is no bar when there is no value for a previous day. I suppose both are expected behavior as its either performing a calculation on a higher previous value or there is no value present to do the calculation on.
Ah, that was a little unclear. What I meant is that you need a second monthly date histogram bucket aggregation (as a split series) additionally to your daily date histogram for the x axis. This will effectively reset the count every month. Make sure the split series aggregation is the first one in the list
Apache, Apache Lucene, Apache Hadoop, Hadoop, HDFS and the yellow elephant
logo are trademarks of the
Apache Software Foundation
in the United States and/or other countries.