
This post is also available in English.
Bem vindo ao dia 20 do nosso Calendário do Advento! Atras da porta de de hoje não encontrarems whisky (como eu geralmente encontro), mas algo melhor para um engneheiro de software: um mistério de performance com um final feliz.
Eu trabalhei em uma nova funcionalidade que deveria ter diminuido a performance da ingestão de logs do Elastic Agent e Filebeat, spolier alert, para a nossa surpresa, isso não aconteceu.
A funcionalidade: ingerindo logs compactados com GZIP
Por que alguém iria querer ingerir logs compactados em GZIP? Bem, logs costumam ser rotacionados: os novos logs vão para o arquivo de log "ativo", enquanto os logs antigos são mantidos em outros arquivos, os chamados logs rotacionados. Para otimizar o armazenamento, esses logs rotacionados são compactados com GZIP. Para nós, o principal caso de uso é a coleta de logs de aplicações rodando no Kubernetes, incluindo os logs rotacionados que acabam sendo comprimidos em GZIP.
Se você está pensando: "mas minha aplicação roda no Kubernetes e apenas loga no standard out, não existe arquivo de log envolvido". Bem, para você pode não haver um arquivo de log, mas para nós — que coletamos os logs, os enviamos para o Elasticsearch (ou outro armazenamento permanente) e os tornamos disponíveis para você no Kibana (ou outro frontend) — todos eles são arquivos de log.
Em resumo: no Kubernetes, um container loga no standard out (stdout) e standard error (stderr). O kubelet lê srdout and stderr e os salva em um arquivo de log. O Elastic Agent e o Filebeat leem esses arquivos, os processam e os enviam para o Elasticsearch. Se tiver curiosidade, você pode conferir a arquitetura de logging do Kubernetes.
O padrão GZIP permite streaming durante a compressão e descompressão. Isso significa que não precisamos descompactar o arquivo inteiro; podemos apenas lê-los, bit a bit, e descompactar on-the-fly conforme a leitura avança.
Além disso, alguns outros requisitos para a funcionalidade foram:
- Rastreamento de offset / leitura parcial: capacidade de retomar a leitura se o arquivo não tiver sido lido completamente. Somos os únicos no mercado que suportam isso

- Identificação de arquivos por fingerprint nos dados descompactados: reconhecer que um arquivo que foi visto primeiro como texto simples (plain text) e depois como GZIP é, na verdade, o mesmo arquivo.
Elastic Agent e Filebeat: uma visão rápida
Uma visão geral rápida sobre os componentes envolvidos, para você não se perder nos termos que vou usar:
Filebeat: um coletor (shipper) leve para logs. É um dos "Beats"; cada Beat ingere um tipo de dado. O Filebeat ingere arquivos (que surpresa!).
Elastic Agent: a solução gerenciada "tudo em um". "O Elastic Agent é uma forma unificada de adicionar monitoramento de logs, métricas e outros tipos de dados a um host."
O Elastic Agent configura e roda os Beats "por baixo dos panos" para coletar os dados desejados. Ele pode ser gerenciado centralmente pelo Fleet ou de forma autônoma (standalone).
O Filebeat pode coletar dados de diferentes fontes; para cada fonte, o componente que coleta os dados é chamado de input. O filestream é o input usado para ingerir arquivos de log. Após a leitura, os dados são processados na Pipeline e enviados para o output, que despacha os dados para um armazenamento permanente (ex: Elasticsearch) ou para processamento posterior (ex: Logstash).
Processo de desenvolvimento
Como esperávamos que essa funcionalidade reduzisse a performance geral de ingestão de logs, começamos com uma prova de conceito (POC - proof of concept), isolando a parte do filestream que realmente lê os arquivos e fazendo um benchmark comparando com a leitura de arquivos comuns. Como previsto, foi mais lento, mas não a ponto de ser proibitivo.

Então, decidimos seguir com a implementação. Uma vez concluída, faríamos o benchmark final para entender o impacto na performance e explicar aos nossos usuários o que esperar ao ingerir arquivos GZIP.
Benchmarks
Temos dois tipos diferentes de benchmark: end-to-end e os micro-benchmarks padrão do Go.
End-to-end
Usamos uma ferramenta interna chamada “benchbuilder” para realizar testes de ponta a ponta dos Beats (filebeat, metricbeat, etc.) e do Elastic Agent. O foco é a experiência do usuário, utilizando logs por segundo (referidos aqui como eventos por segundo ou EPS) como métrica principal. É mais complexo e exige um setup extenso.
Go / micro-benchmarks
Benchmarks padrão de Go, testando uma função ou um componente pequeno para avaliar se uma nova implementação é de fato melhor ou se não estamos degradando a performance com novas funcionalidades ou refatorações. É fácil e barato de desenvolver e rodar.
O que medimos
- EPS (eventos por segundo): quão rápido conseguimos entregar os logs.
- Uso de CPU: quanta CPU é utilizada.
- Uso de Memória: quanta memória é necessária.
Casos de uso
- Muitos arquivos pequenos: milhares de arquivos de 10MB. Isso simula a rotação de logs do Kubernetes em um ambiente com high-load.
- 1 arquivo gigante: vários GBs. Para garantir que funcione com arquivos maiores que a memória disponível.
O primeiro benchmark (ainda inacabado)


Para nossa surpresa, o arquivo de 10MB gzippado foi, por uma pequena margem, mais rápido!
Vamos olhar todos os benchmarks para tentar entender esses resultados.
Comparando de EPS
1 arquivo de 45GB e 4150 arquivos de 10MB cada
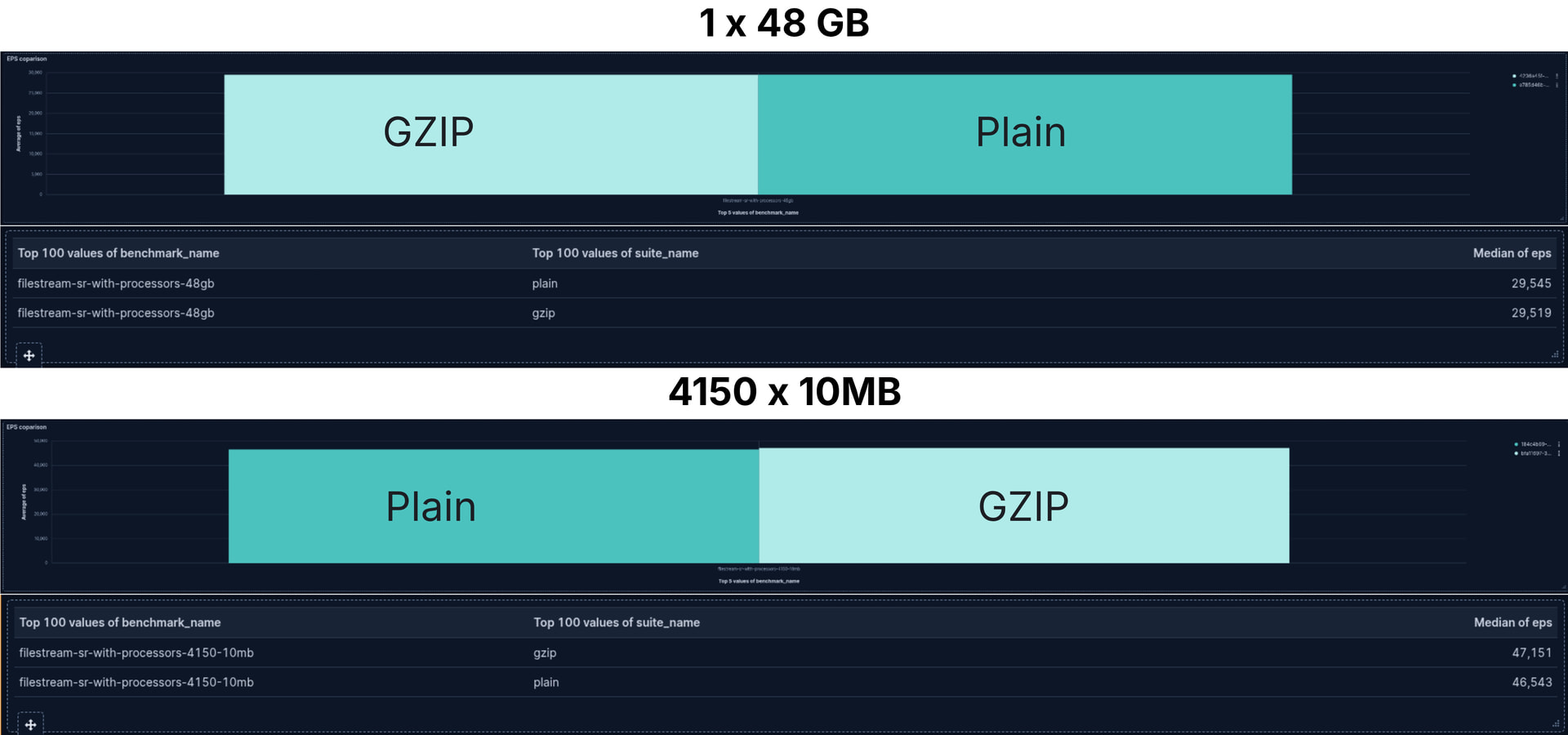
Que surpresa! A diferença no throughput (os eventos enviados ao Elasticsearch por segundo) foi insignificante. Não apenas isso, mas no caso dos 4150 arquivos pequenos, ler arquivos GZIP foi um pouquinho mais rápido.
Uso de CPU


Novamente, para o uso de CPU, não vemos diferença real. O que observamos é que ler milhares de arquivos pequenos consome mais CPU do que ler um único arquivo grande. Como esperado. Há muita coisa acontecendo entre detectar que um novo arquivo existe, abri-lo para leitura e fechá-lo quando estiver pronto.
Uso de Memória

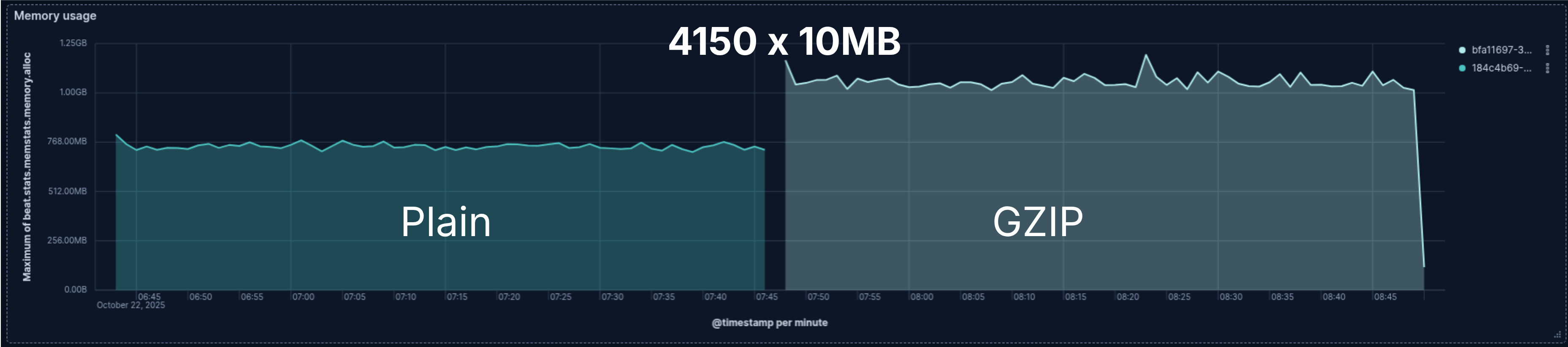
Finalmente, ao menos uma vez, o senso comum venceu! Bem, foi só meia vitória.
Ler os 4150 arquivos GZIP exigiu mais memória do que seus equivalentes em texto puro. No entanto, embora o consumo de memória durante a leitura do arquivo de 48GB não seja exatamente estável, tanto o arquivo comum quanto o GZIP usam quase a mesma quantidade de memória.
Com os testes end-to-end, micro-benchmarks em Go e sabendo como a biblioteca de descompressão GZIP funciona, determinamos que há um aumento de cerca de 100KB de memória por arquivo GZIP sendo lido. É por isso que não vemos impacto na descompressão GZIP ao ler um arquivo de 48GB; os 100KB extras são irrelevantes no consumo total de memoria.
Por outro lado, isso se torna significativo quando milhares de arquivos são lidos ao mesmo tempo. Pode ser necessário levar isso em conta. O número de arquivos sendo lidos em paralelo e quando eles são fechados pode ser configurado para ajudar a mitigar o impacto desse aumento de memória.
Entendendo os resultados
Ok, sabemos que os dados não mentem (pelo menos se o experimento e a coleta foram bem feitos, o que foi o caso aqui). Então, por que os dados parecem ir contra o senso comum e meus primeiros benchmarks?
Entendendo como o Filebeat funciona
Como mencionei no início, o Filebeat é quem faz o trabalho pesado de ler os arquivos; o Elastic Agent apenas executa o Filebeat "por baixo do panos".
O Filebeat (e qualquer outro Beat) tem internamente três componentes principais: Input, Queue/Pipeline e Output.

Input: filestream
O input é o componente que realmente lê os dados e os publica para a Pipeline. Em nossos benchmarks em Go (como o primeiro que mostrei), vemos que o filestream é mais lento ao ler arquivos GZIP. Micro-benchmarks adicionais confirmaram isso. Os dados são lidos em um ritmo mais lento e enviados para a fila do Pipeline.
Pipeline / Queue
É no Pipeline que os dados coletados são processados e transformados. Os processors fazem parte da Pipeline. Eles transformam os dados, adicionando, modificando ou removendo campos nos logs. Como eles modificam a forma dos dados, os processadores são aplicados em sequência. O output de um processor é o input do próximo:
evento -> processador 1 -> evento1 -> processador 2 -> evento2 ...
Algumas transformações são destrutivas, o que significa que não podem ser revertidas, especialmente se falharem. Assim, para garantir a integridade dos dados se algum processor falhar, abortamos a pipeline e publicamos o output do último processor bem-sucedido. Isso garante que entreguemos dados consistentes mesmo em caso de falha. Para os processadores que realizam ações destrutivas, eles são aplicados a uma cópia do log. Essa operação de cópia geralmente envolve alocação de memória e tem um custo de performance.
Dito isso, remover os processadores deveria revelar a lentidão do GZIP, certo?


Sim e não! De fato, os processors têm um overhead considerável: com eles, o EPS fica em torno de 20.000; sem eles, sobe para 25.000. É consideravelmente mais rápido. No entanto, a diferença entre GZIP e arquivos comuns continua insignificante.
Não apenas os processors são aplicados em sequência, mas os logs também são processados em sequência. Existe uma fila entre o input, o pipeline e o output. Como em qualquer fila (de pessoas ou de logs), se ela não "anda rápido o suficiente" e chegam novos itens mais rápido do que saem, a fila só cresce. O input é como um corredor rápido preso atrás de uma fila que se move devagar.
No Filebeat, quando a fila está cheia, o input para de ler dados e espera até que haja espaços vazios na fila.
É exatamente isso que está acontecendo! O filestream é mais rápido que o Pipeline — muito mais rápido. Tanto que, mesmo quando fica mais lento devido à descompressão de GZIP, ele ainda é mais rápido que a Pipeline. O input (filestream) bloqueia, para de ler dados e espera espaços abrirem na fila para continuar.
Isso também alinha com o que observamos ao ajudar usuários a otimizar o throughput do Filebeat: boa parte do trabalho consiste em encontrar a configuração de fila ideal para o caso de uso.
Conclusão
Quando o assunto é performance, nunca tente adivinhar — sempre meça!
Meça tudo: as mudanças locais e micro, bem como a aplicação de ponta a ponta (idealmente como uma "caixa preta"). Um ganho ou perda de performance em uma parte da aplicação pode não impactar a performance global como esperado.
Agora sabemos que temos margem no filestream para adicionar funcionalidades que podem reduzir seu throughput individual sem afetar a performance geral da aplicação. Ao mesmo tempo, se quisermos melhorar a performance global, devemos focar nossos esforços no Pipeline, nos Processadores e na Fila.
Boa coleta de logs!