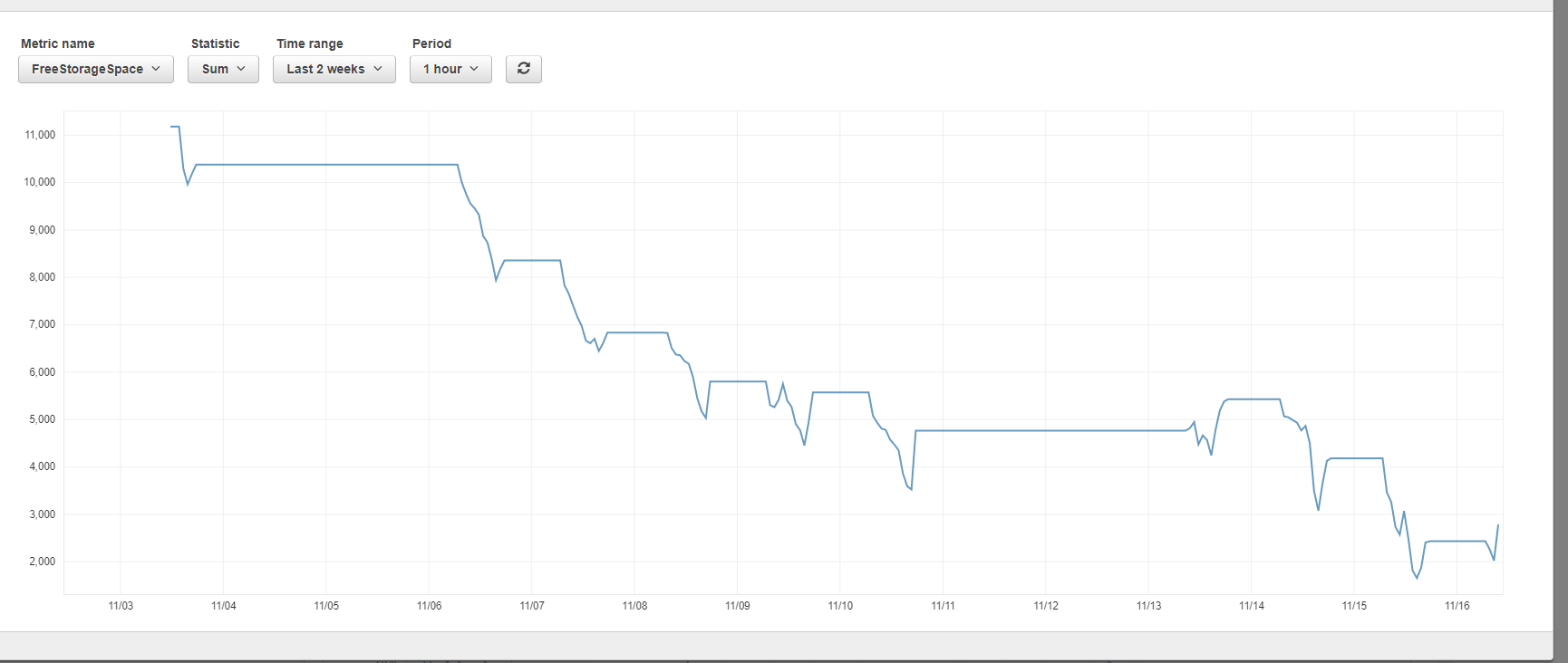
Hello I have a job that deletes elastic indices per hour using the curator. It has been working fine, old shards and index are gone but when I check the amount of free space I have... it is less and less.
If the indices are being deleted, and the graph seems to indicate that they are (the "climbs" back up after the "dips" in the space chart), then it's not Curator, or even necessarily Elasticsearch. It could be something at the OS-level not deleting quickly enough due to high I/O. I do not know enough about the instances AWS Elasticsearch runs on to know what's going on under the hood.
Glancing at your _cat API output, hourly indices are overkill for you. They are tiny. You should be using the rollover API and letting your indices get much bigger before rolling over, and subsequently deleting. Each shard in Elasticsearch has an overhead, regardless of how much space it consumes, or how many documents it holds. Too many shards per node results in memory pressure and everything that comes with it. Too many shards per node could be part of your problem.
Apache, Apache Lucene, Apache Hadoop, Hadoop, HDFS and the yellow elephant
logo are trademarks of the
Apache Software Foundation
in the United States and/or other countries.