I have a query for daily login retention, which gets sub-buckets (by term filter) of each day (date histogram). Instead of absolute values, I would like to know percentage of each sub-bucket to the parent bucket count.
I would like to calculate the sub-buckets doc_count / parent buckets doc_count * 100, so percentage of total rows. So If i have a doc_count of 3 before the filter and three sub-buckets with doc_counts of 1, 2 and 3 respectively I should get 33%, 66% and 100% values to be shown in the graph.
If you are using the standard visualization editor, you can configure this by setting the "Mode" of the y axis to "percentage" in the "Metrics & Axes" tab on the left side (second dropdown from the bottom in the screenshot):
This is not working as exptected. It calculates percentage against total sum of sibling buckets (sum is always 100) and I need a percentage against the total parent doc_count.
Example bucket:
doc_count (100, total of users)
iphone_users (10, total of users with iphone). this should be 10%
android_users (55, total of users with android). this should be 55%
Your example would give a percentages of 15,38% and 84,62%. Should be 10% and 55%.
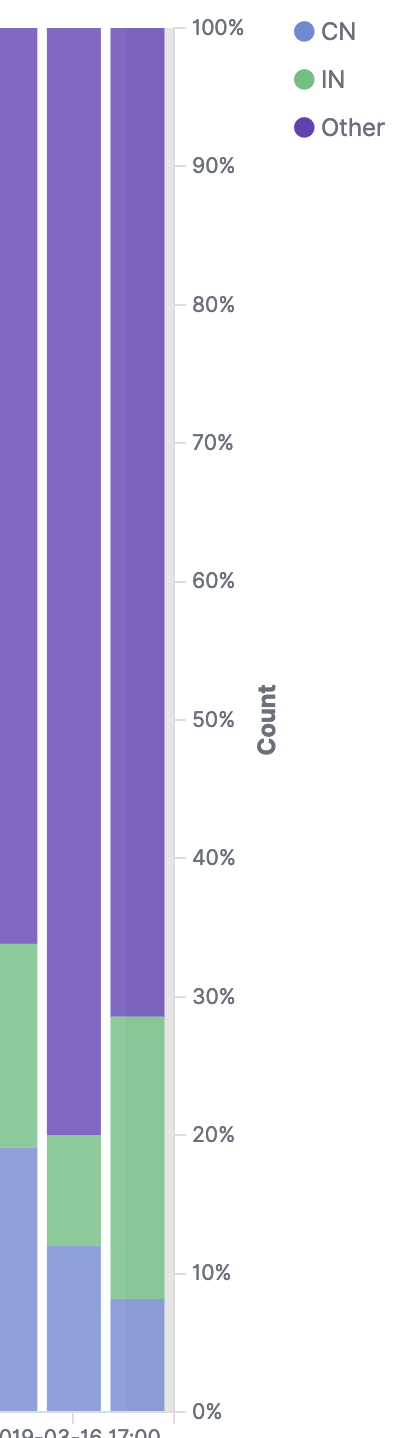
Each column will still add up to 100%, but this setting should add a separate label "Other" - so in your example you should have iphone_users 10%, android_users 55% and Other 35%
Like in the screenshot - everything adds up to 100%, but the percentages are calculated correctly for the two "named buckets", in this case "IN" and "CN"
Without Other bucket:
Apache, Apache Lucene, Apache Hadoop, Hadoop, HDFS and the yellow elephant
logo are trademarks of the
Apache Software Foundation
in the United States and/or other countries.