I'm not sure I'm fully understanding what you want to do.
I want to find similar tweets based on text
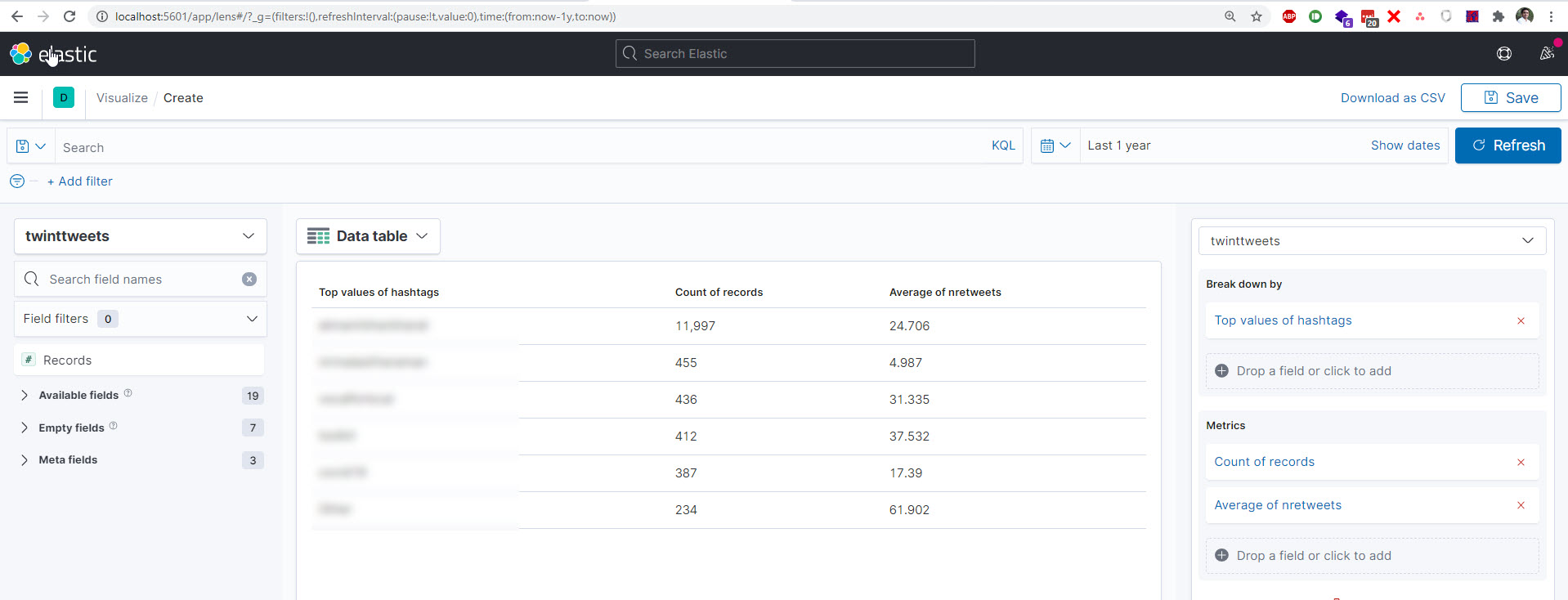
What's "similar" here? Do you mean exactly the same text? If that's the case you can use the "Top values" function for the tweet field together with the "Count" function in Lens.
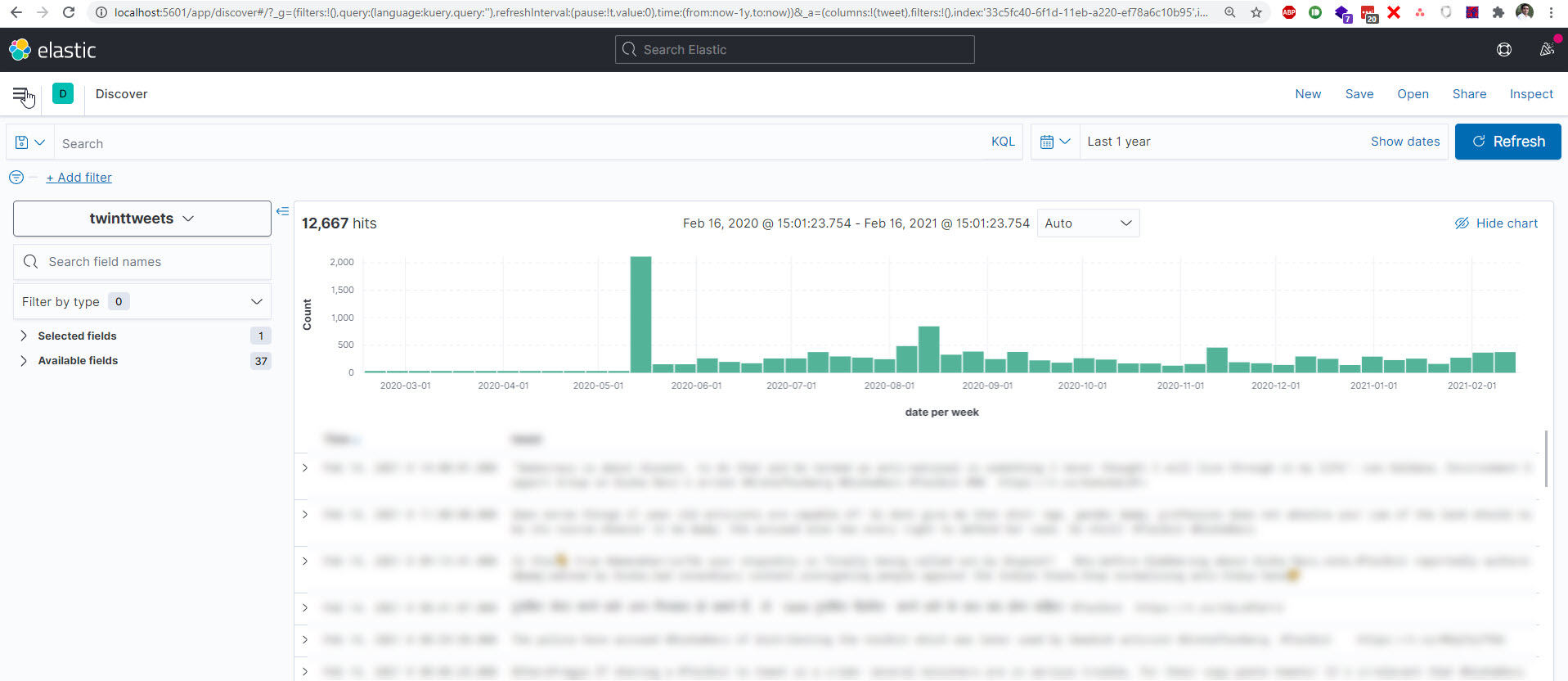
OK, so the difference between the Discover and Lens views are Discover working on individual documents while Lens works with aggregated data only.
Depending on how your index is configured, not all fields are aggregatable. For Discover this doesn't matter - it can still show all of them. But in Lens, the list of fields is pre-filtered.
If you go to Management > Index patterns you can see this:
agent.keyword is usable in Lens and will show up in the list, while agent is not. In Discover, you can use both fields.
If the tweet message field shows up in Discover but not in Lens it means it's not aggregatable. To fix this, you have to change your mapping and make sure it's indexed as "keyword" (not only text). Then you need to re-index your existing data so the aggregatable index is built within Elasticsearch.
A common mapping to use (like in the screenshot above) is to have the original field indexed as "text" for full text search with a second field suffixed with ".keyword" for the keyword indexed version of the same data for aggregations. This gives you the best of both worlds:
This tries to set the mapping for the tweet type, not the tweet field. I think the best approach is to create a completely new index mapping (maybe twinttweets_fixed) with all fields, including the keyword version of the tweet field, then use the re-index api to shovel the data from twinttweets to twinttweets_fixed.
Apache, Apache Lucene, Apache Hadoop, Hadoop, HDFS and the yellow elephant
logo are trademarks of the
Apache Software Foundation
in the United States and/or other countries.