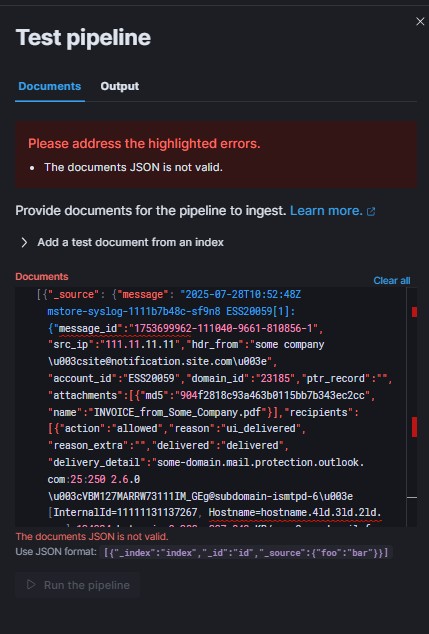
I'm trying to create an ingest pipeline using a grok porcessor to strip the syslog header and a json processor to extract the json portion of the message.
Here's the structure of the messages I need to ingest:
2025-07-28T10:52:48Z mstore-syslog-1111b7b48c-sf9n8 ESS20059[1]: {"message_id":"1753699962-111040-9661-810856-1","src_ip":"111.11.11.11","hdr_from":"some company \u003csite@notification.site.com\u003e","account_id":"ESS20059","domain_id":"23185","ptr_record":"","attachments":[{"md5":"904f2818c93a463b0115bb7b343ec2cc","name":"INVOICE_from_Some_Company.pdf"}],"recipients":[{"action":"allowed","reason":"ui_delivered","reason_extra":"","delivered":"delivered","delivery_detail":"some-domain.mail.protection.outlook.com:25:250 2.6.0 \u003cVBM127MARRW73111IM_GEg@subdomain-ismtpd-6\u003e [InternalId=11111131137267, Hostname=hostname.4ld.3ld.2ld.com] 134234 bytes in 0.388, 337.842 KB/sec Queued mail for delivery","email":"user@some_domain.com","taxonomy":"policy"}],"hdr_to":"user@some_domain.com","recipient_count":1,"dst_domain":"some_domain.com","size":122243,"subject":"Phishing Attack verbage","env_from":"bounces+1117135-bef1-user=some_domain.com@e.notification.site.com","timestamp":"2025-07-28T10:52:45+0000","geoip":"","tls":true,"hdr_auth_results":""}
I run the message format above through the grok debugger in Kibana, using the following pattern, which is the same as the one used in the grok processor.
%{NOTSPACE} %{NOTSPACE} %{NOTSPACE} %{GREEDYDATA:syslog_message_content}
It produces the following results:
{
"syslog_message_content": "{\"message_id\":\"1753699962-111040-9661-810856-1\",\"src_ip\":\"111.11.11.11\",\"hdr_from\":\"some company \\u003csite@notification.site.com\\u003e\",\"account_id\":\"ESS20059\",\"domain_id\":\"23185\",\"ptr_record\":\"\",\"attachments\":[{\"md5\":\"904f2818c93a463b0115bb7b343ec2cc\",\"name\":\"INVOICE_from_Some_Company.pdf\"}],\"recipients\":[{\"action\":\"allowed\",\"reason\":\"ui_delivered\",\"reason_extra\":\"\",\"delivered\":\"delivered\",\"delivery_detail\":\"some-domain.mail.protection.outlook.com:25:250 2.6.0 \\u003cVBM127MARRW73111IM_GEg@subdomain-ismtpd-6\\u003e [InternalId=11111131137267, Hostname=hostname.4ld.3ld.2ld.com] 134234 bytes in 0.388, 337.842 KB/sec Queued mail for delivery\",\"email\":\"user@some_domain.com\",\"taxonomy\":\"policy\"}],\"hdr_to\":\"user@some_domain.com\",\"recipient_count\":1,\"dst_domain\":\"some_domain.com\",\"size\":122243,\"subject\":\"Phishing Attack verbage\",\"env_from\":\"bounces+1117135-bef1-user=some_domain.com@e.notification.site.com\",\"timestamp\":\"2025-07-28T10:52:45+0000\",\"geoip\":\"\",\"tls\":true,\"hdr_auth_results\":\"\"}"
}
As you can see, the grok debugger inserts backslashes before all the double quote and backslash characters. I'm wondering if this is a result of the grok debugger output having to be displayed in a webpage. Does the grok processor actually insert these backslashes before it passes its output to the next processsor?
Here's my grok processor config.

Here's my json processor config.

TIA,
Brad