こんにちわ。
最終的な絵がどんなものか想像でしかないのですが、こんなドーナツチャートを期待されているのでしょうか。
このようにするのであれば、tasksやactionを1つの文字列の値ではなく、Arrayとして持つ必要があるように思います。
具体的に言うと、
"task" : "\"経理\",\"法務\""
のようではなく、以下のようなイメージです。
"task" : ["経理", "法務"]
CSVインポートで試されているとのことなので、CSV取込時に加工する手順(Ingest pipeline)があるので、これを使うと実現できるのではないかと考えております。
再現手順
テスト用データ
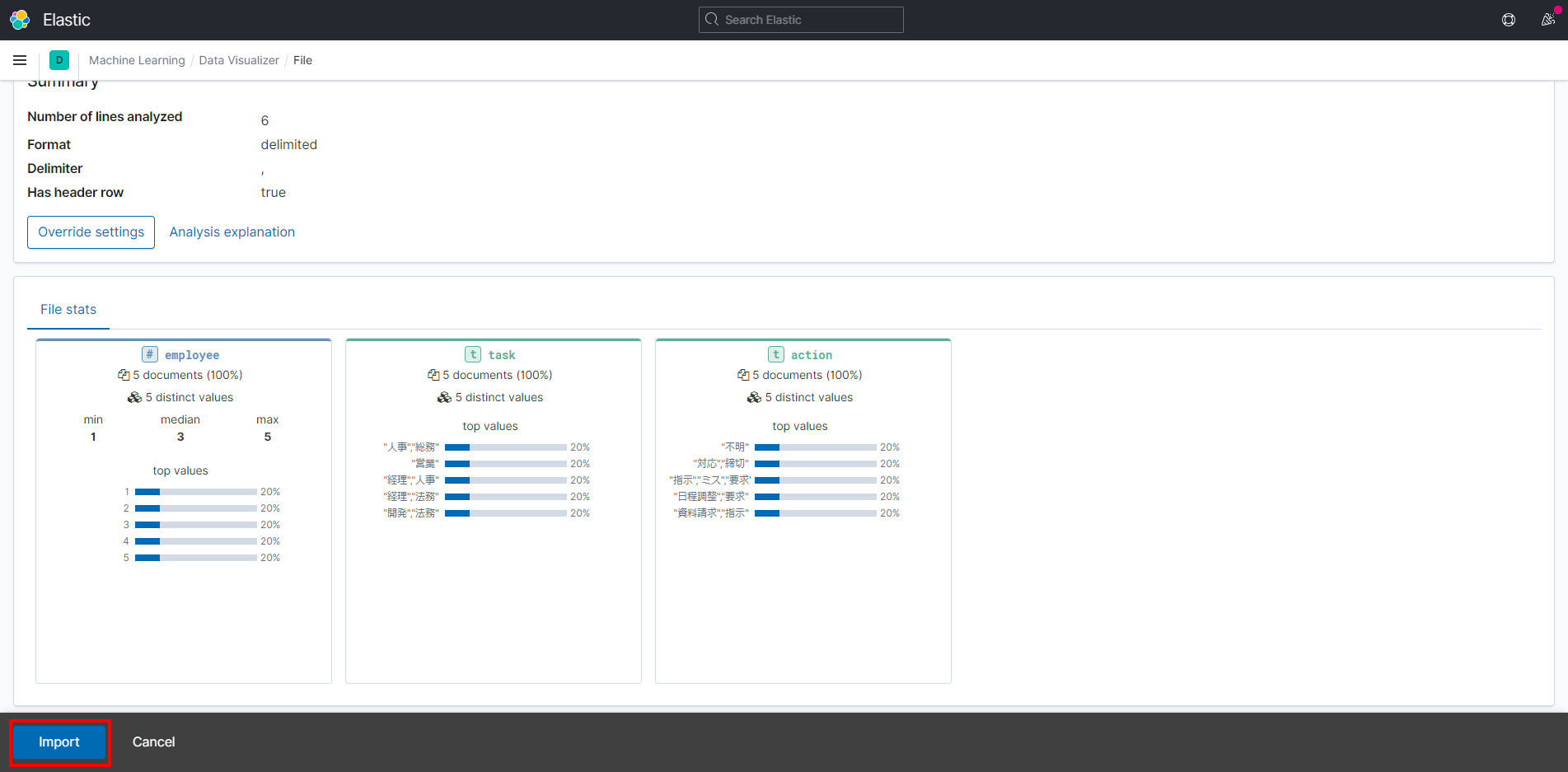
インポートするcsvファイルを用意します。 ”は画像で提示されたデータにあったため入れています。
employee,task,action
00001,"""経理"",""法務""","""指示"",""ミス"",""要求"""
00002,"""人事"",""総務""","""対応"",""締切"""
00003,"""営業""","""日程調整"",""要求"""
00004,"""開発"",""法務""","""不明"""
00005,"""経理"",""人事""","""資料請求"",""指示"""
Machine Learning / Data Visualizerを開く
Upload fileを選択します。遷移先の画面で先に作成したCSVファイルをDrag&Dropします
Importボタンを押下します
Advancedを選択して、MappingsとIngest pipelineのところを変更します
大まかな処理の流れは以下となっています。
1.1行のCSVデータを、それぞれのフィールドに分ける
2.taskとactionのフィールドに入っている値は、 , で分割して配列にする
3.不要な ” を置換処理にて削除する
Ingest pipelineに設定している値は次の通りです。
{
"description": "CSV取込時にデータを加工して変換する",
"processors": [
{
"csv": {
"field": "message",
"target_fields": [
"employee",
"task",
"action"
],
"ignore_missing": false
}
},
{
"remove": {
"field": "message"
}
},
{
"split": {
"field": "task",
"separator": ","
}
},
{
"split": {
"field": "action",
"separator": ","
}
},
{
"gsub": {
"field": "task",
"pattern": "\"",
"replacement": ""
}
},
{
"gsub": {
"field": "action",
"pattern": "\"",
"replacement": ""
}
}
]
}
あとはImportボタンを押下します。
VisualizeでLensを選択します
tasksとactionをLensで可視化した絵が冒頭の絵になります。
ご参考になれば幸いです。