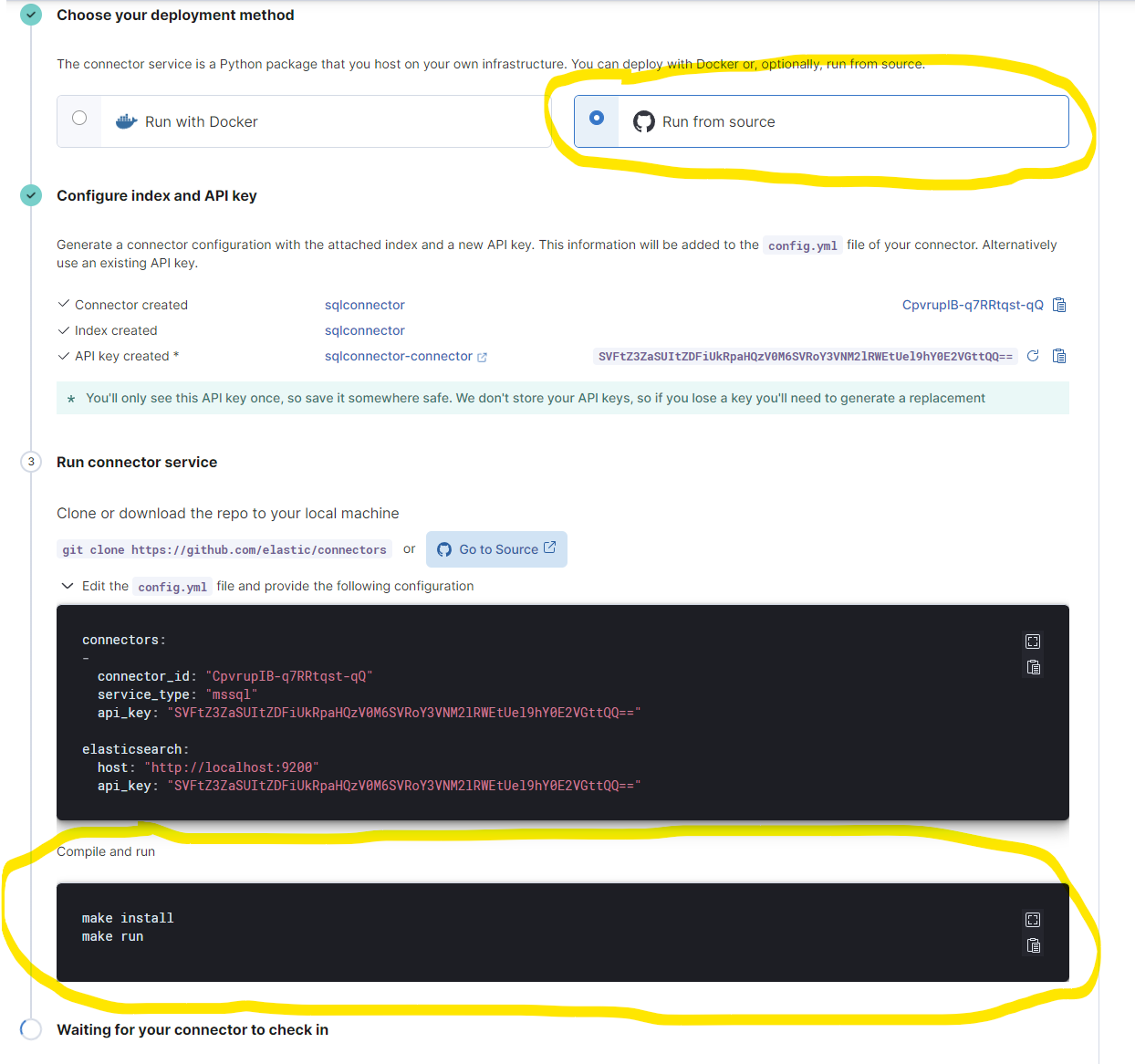
Hi Everyone,
I'm trying do MS SQL connector configuration in Kibana using Docker but I can't continue because I can't run it in Docker and here is the instruction I'm following:



config.yml after editing
## ================= Elastic Connectors Configuration ==================
#
## NOTE: Elastic Connectors comes with reasonable defaults.
## Before adjusting the configuration, make sure you understand what you
## are trying to accomplish and the consequences.
#
#
## ------------------------------- Connectors -------------------------------
#
## The list of connector clients/customized connectors configurations.
## Each object in the list requires `connector_id` and `service_type`.
## An example is:
## connectors:
## - connector_id: changeme # the ID of the connector.
## service_type: changeme # The service type of the connector.
## api_key: changeme # The Elasticsearch API key used to write data into the content index.
#connectors: []
#
#
## The ID of the connector.
## (Deprecated. Configure the connector client in an object in the `connectors` list)
#connector_id: null
#
#
## The service type of the connector.
## (Deprecated. Configure the connector client in an object in the `connectors` list)
#service_type: null
#
#
## ------------------------------- Elasticsearch -------------------------------
#
## The host of the Elasticsearch deployment.
#elasticsearch.host: http://localhost:9200
#
#
## The API key for Elasticsearch connection.
## Using `api_key` is recommended instead of `username`/`password`.
#elasticsearch.api_key: null
#
#
## The username for the Elasticsearch connection.
## Using `username` requires `password` to also be configured.
## However, `elasticsearch.api_key` is the recommended configuration choice.
#elasticsearch.username: elastic
#
#
## The password for the Elasticsearch connection.
## Using `password` requires `username` to also be configured.
## However, `elasticsearch.api_key` is the recommended configuration choice.
#elasticsearch.password: changeme
#
#
## Whether SSL is used for the Elasticsearch connection.
#elasticsearch.ssl: true
#
#
## Path to a CA bundle, e.g. /path/to/ca.crt
#elasticsearch.ca_certs: null
#
#
## Whether to retry on request timeout.
#elasticsearch.retry_on_timeout: true
#
#
## The request timeout to be passed to transport in options.
#elasticsearch.request_timeout: 120
#
#
## The maximum wait duration (in seconds) for the Elasticsearch connection.
#elasticsearch.max_wait_duration: 60
#
#
## The initial backoff duration (in seconds).
#elasticsearch.initial_backoff_duration: 1
#
#
## The backoff multiplier.
#elasticsearch.backoff_multiplier: 2
#
#
## Elasticsearch log level
#elasticsearch.log_level: INFO
#
#
## Maximum number of times failed Elasticsearch requests are retried, except bulk requests
#elasticsearch.max_retries: 5
#
#
## Retry interval between failed Elasticsearch requests, except bulk requests
#elasticsearch.retry_interval: 10
#
#
## ------------------------------- Elasticsearch: Bulk ------------------------
#
## Options for the Bulk API calls behavior - all options can be
## overridden by each source class
#
#
## The number of docs between each counters display.
#elasticsearch.bulk.display_every: 100
#
#
## The max size of the bulk queue
#elasticsearch.bulk.queue_max_size: 1024
#
#
## The max size in MB of the bulk queue.
## When it's reached, the next put operation waits for the queue size to
## get under that limit.
#elasticsearch.bulk.queue_max_mem_size: 25
#
#
## Minimal interval of time between MemQueue checks for being full
#elasticsearch.bulk.queue_refresh_interval: 1
#
#
## Maximal interval of time during which MemQueue does not dequeue a single document
## For example, if no documents were sent to Elasticsearch within 60 seconds because of
## Elasticsearch being overloaded, then an error will be raised.
## This mechanism exists to be a circuit-breaker for stuck jobs and stuck Elasticsearch.
#elasticsearch.bulk.queue_refresh_timeout: 60
#
#
## The max size in MB of a bulk request.
## When the next request being prepared reaches that size, the query is
## emitted even if `chunk_size` is not yet reached.
#elasticsearch.bulk.chunk_max_mem_size: 5
#
#
## The max size of the bulk operation to Elasticsearch.
#elasticsearch.bulk.chunk_size: 500
#
#
## Maximum number of concurrent bulk requests.
#elasticsearch.bulk.max_concurrency: 5
#
#
## Maximum number of concurrent downloads in the backend.
#elasticsearch.bulk.concurrent_downloads: 10
#
#
## Maximum number of times failed bulk requests are retried
#elasticsearch.bulk.max_retries: 5
#
#
## Retry interval between failed bulk attempts
#elasticsearch.bulk.retry_interval: 10
#
#
## Enable to log ids of created/indexed/deleted/updated documents during a sync.
## This will be logged on 'DEBUG' log level. Note: this depends on the service.log_level, not elasticsearch.log_level
#elasticsearch.bulk.enable_operations_logging: false
#
## ------------------------------- Elasticsearch: Experimental ------------------------
#
## Experimental configuration options for Elasticsearch interactions.
#
#
## Enable usage of Connectors API instead of calling connectors indices directly
#elasticsearch.feature_use_connectors_api: false
## ------------------------------- Service ----------------------------------
#
## Connector service/framework related configurations
#
#
## The interval (in seconds) to poll connectors from Elasticsearch.
#service.idling: 30
#
#
## The interval (in seconds) to send a new heartbeat for a connector.
#service.heartbeat: 300
#
#
## The maximum number of retries for pre-flight check.
#service.preflight_max_attempts: 10
#
#
## The number of seconds to wait between each pre-flight check.
#service.preflight_idle: 30
#
#
## The maximum number of errors allowed in one event loop.
#service.max_errors: 20
#
#
## The number of seconds to reset `max_errors` count.
#service.max_errors_span: 600
#
#
## The maximum number of concurrent content syncs.
#service.max_concurrent_content_syncs: 1
#
#
## The maximum number of concurrent access control syncs.
#service.max_concurrent_access_control_syncs: 1
#
#
## The maximum size (in bytes) of files that the framework should be willing
## to download and/or process.
#service.max_file_download_size: 10485760
#
## The interval (in seconds) to run job cleanup task.
#service.job_cleanup_interval: 300
#
#
## Connector service log level.
#service.log_level: INFO
#
#
## ------------------------------- Extraction Service ----------------------------------
#
## Local extraction service-related configurations.
## These configurations are optional and are not included by default.
## The presence of these configurations enables local content extraction.
## By default, this whole object is `null`.
## See: https://www.elastic.co/guide/en/enterprise-search/current/connectors-content-extraction.html#connectors-content-extraction-local
#
#
## The host of the local extraction service.
#extraction_service.host: null
#
#
## Request timeout for local extraction service requests, in seconds.
#extraction_service.timeout: 30
#
#
## Whether or not to use file pointers for local extraction.
## This can have very positive impacts on performance -
## both speed and memory consumption.
## However, it also requires that the Connectors deployment and the
## local extraction service deployment must share a filesystem.
#extraction_service.use_file_pointers: False
#
#
## The size (in bytes) that files are chunked to for streaming when sending
## a file to the local extraction service.
## Only applicable if `extraction_service.use_file_pointers` is `false`.
#extraction_service.stream_chunk_size: 65536
#
#
## The location for files to be extracted from.
## Only applicable if `extraction_service.use_file_pointers` is `true`.
#extraction_service.shared_volume_dir: /app/files
#
#
## ------------------------------- Sources ----------------------------------
#
## An object mapping service type names to class Fully Qualified Names
## E.g. `connectors.sources.mongo:MongoDataSource`.
## If adding a net-new connector, it must be added here for the framework to detect it.
## Default includes all tech preview, beta, and GA connectors in this repository.
## An example is:
## sources:
## mongodb: connectors.sources.mongo:MongoDataSource
connectors:
-
connector_id: "CpvrupIB-q7RRtqst-qQ"
service_type: "mssql"
api_key: "SVFtZ3ZaSUItZDFiUkRpaHQzV0M6SVRoY3VNM2lRWEtUel9hY0E2VGttQQ=="
elasticsearch:
host: "http://localhost:9200"
api_key: "SVFtZ3ZaSUItZDFiUkRpaHQzV0M6SVRoY3VNM2lRWEtUel9hY0E2VGttQQ=="
When trying to deploy to docker I'm getting this error:
Is there something wrong with the syntax I'm using? I was able to make it work before
Also If I choose the other option "Run from Source" how to do the make install and make run part?