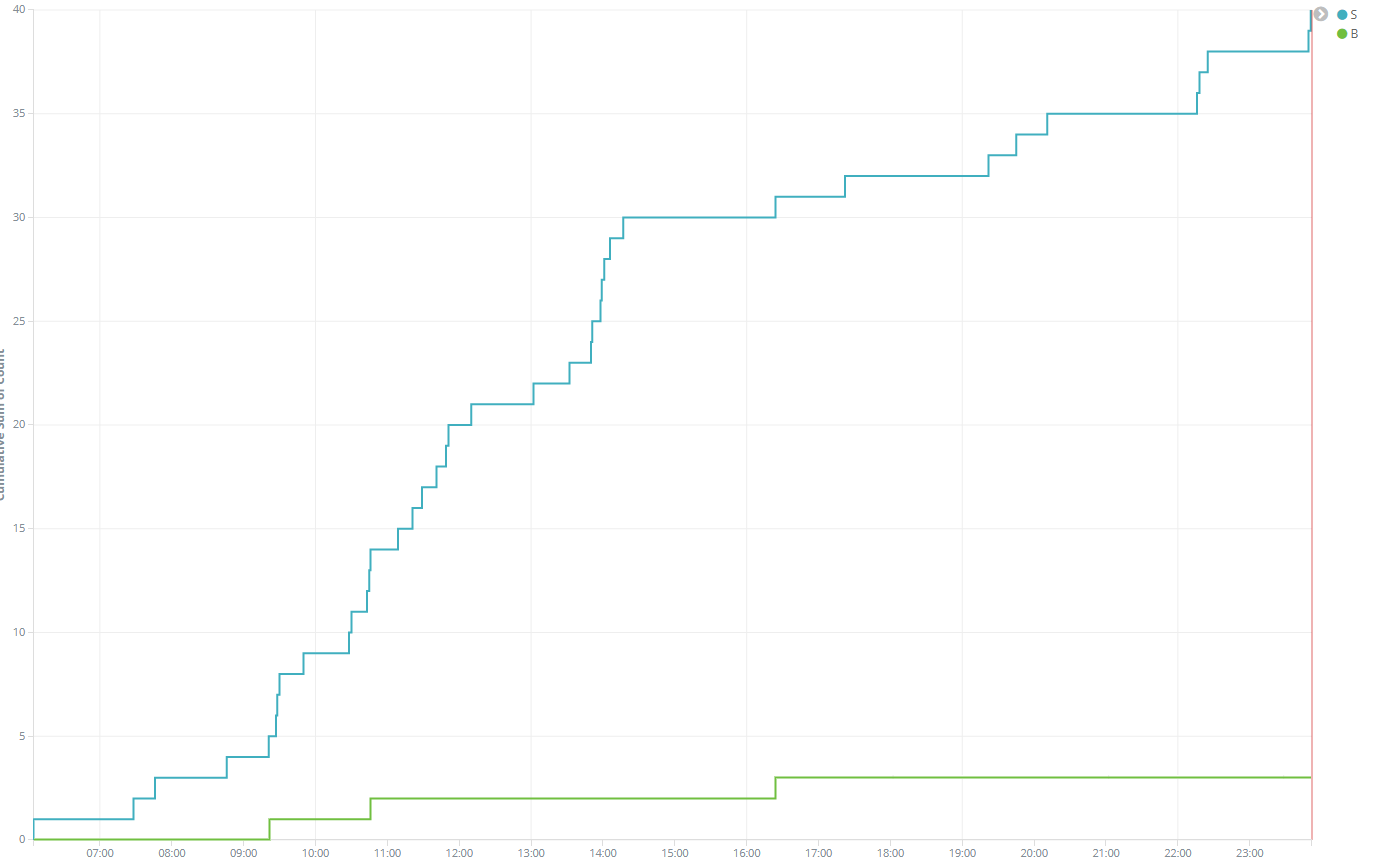
I'm trying to split my series with a keyword and show 2 line charts depending on the keyword value. BUT as you can see below, the green line is not starting at the beginning of the chart (where blue line starts!). What I was thinking is that missing values aren't considered but I tried to add { "min_doc_count":0, "missing": 0 } on the bucket script but still not working...
that;s tough, especially the extension at the right-hand part of your graph, where Kibana needs to be smart enough to extend the last known value. Right now, Kibana uses the bucket-values it gets from ES and does no interpolation.
Apache, Apache Lucene, Apache Hadoop, Hadoop, HDFS and the yellow elephant
logo are trademarks of the
Apache Software Foundation
in the United States and/or other countries.