Hi everyone, I would like some help or an explanation regarding how to work using pre-aggregated data for ML.
Scenario: We’re indexing pre-aggregated data to Elasticsearch. Each document has the following (relevant) fields:
• PageLoadEventCount: how many page load events were aggregated into this document.
• TotalResponseTime: The milliseconds spent waiting for a response during the page load, summed over all events aggregated into this document. To get a proper average response time per page load, this number should be divided by PageLoadEventCount
• Browser
• Timestamp
• Other interesting influencer fields, e.g. Country
I defined an ML job intended to monitor the average response time of page loads. Note that I included the summary_count_field_name, which according to Elasticsearch’s documentation is intended exactly for the use case of analyzing pre-aggregated data. The ML job configuration can be seen here:
{
"job_id" : "ml-avg-response-time-2",
"job_type" : "anomaly_detector",
"job_version" : "5.5.2",
"description" : "",
"create_time" : 1505666647208,
"finished_time" : 1505668033228,
"analysis_config" : {
"bucket_span" : "5m",
"summary_count_field_name" : "PageLoadEventCount",
"detectors" : [{
"detector_description" : "high_mean(TotalResponseTime) over Browser",
"function" : "high_mean",
"field_name" : "TotalResponseTime",
"over_field_name" : "Browser",
"detector_rules" : ,
"detector_index" : 0
}
],
"influencers" : [
"BrowserGroup",
"Country",
"Browser",
"OperatingSystem"
]
},
"data_description" : {
"time_field" : "Timestamp",
"time_format" : "epoch_ms"
},
"model_plot_config" : {
"enabled" : true
},
"model_snapshot_retention_days" : 1,
"model_snapshot_id" : "1507031088",
"results_index_name" : "shared",
"data_counts" : {
"job_id" : "ml-avg-response-time-2",
"processed_record_count" : 146247799,
"processed_field_count" : 10641937,
"input_bytes" : 4349257045,
"input_field_count" : 10641937,
"invalid_date_count" : 0,
"missing_field_count" : 866844857,
"out_of_order_timestamp_count" : 0,
"empty_bucket_count" : 0,
"sparse_bucket_count" : 258,
"bucket_count" : 161864,
"earliest_record_timestamp" : 1504181025000,
"latest_record_timestamp" : 1507030349000,
"last_data_time" : 1507030950314,
"latest_empty_bucket_timestamp" : 1506705300000,
"latest_sparse_bucket_timestamp" : 1505725200000,
"input_record_count" : 146247799
},
"model_size_stats" : {
"job_id" : "ml-avg-response-time-2",
"result_type" : "model_size_stats",
"model_bytes" : 1089490,
"total_by_field_count" : 3,
"total_over_field_count" : 133,
"total_partition_field_count" : 2,
"bucket_allocation_failures_count" : 0,
"memory_status" : "ok",
"log_time" : 1507031088000,
"timestamp" : 1507029900000
},
"datafeed_config" : {
"datafeed_id" : "datafeed-ml-avg-response-time-2",
"job_id" : "ml-avg-response-time-2",
"query_delay" : "600s",
"frequency" : "150s",
"indices" : [
"singledim_agguser*"
],
"types" : [
"singledim_agguser"
],
"query" : {
"match_all" : {
"boost" : 1
}
},
"scroll_size" : 1000,
"chunking_config" : {
"mode" : "auto"
},
"state" : "stopped"
},
"state" : "closed"
}
Looking at the anomaly explorer, this is what I saw:

It claims a spike of avg. response time of about 40 seconds! Looking at the raw data however, I see that this is simply caused by the average not being properly calculated according to the number of page load events:
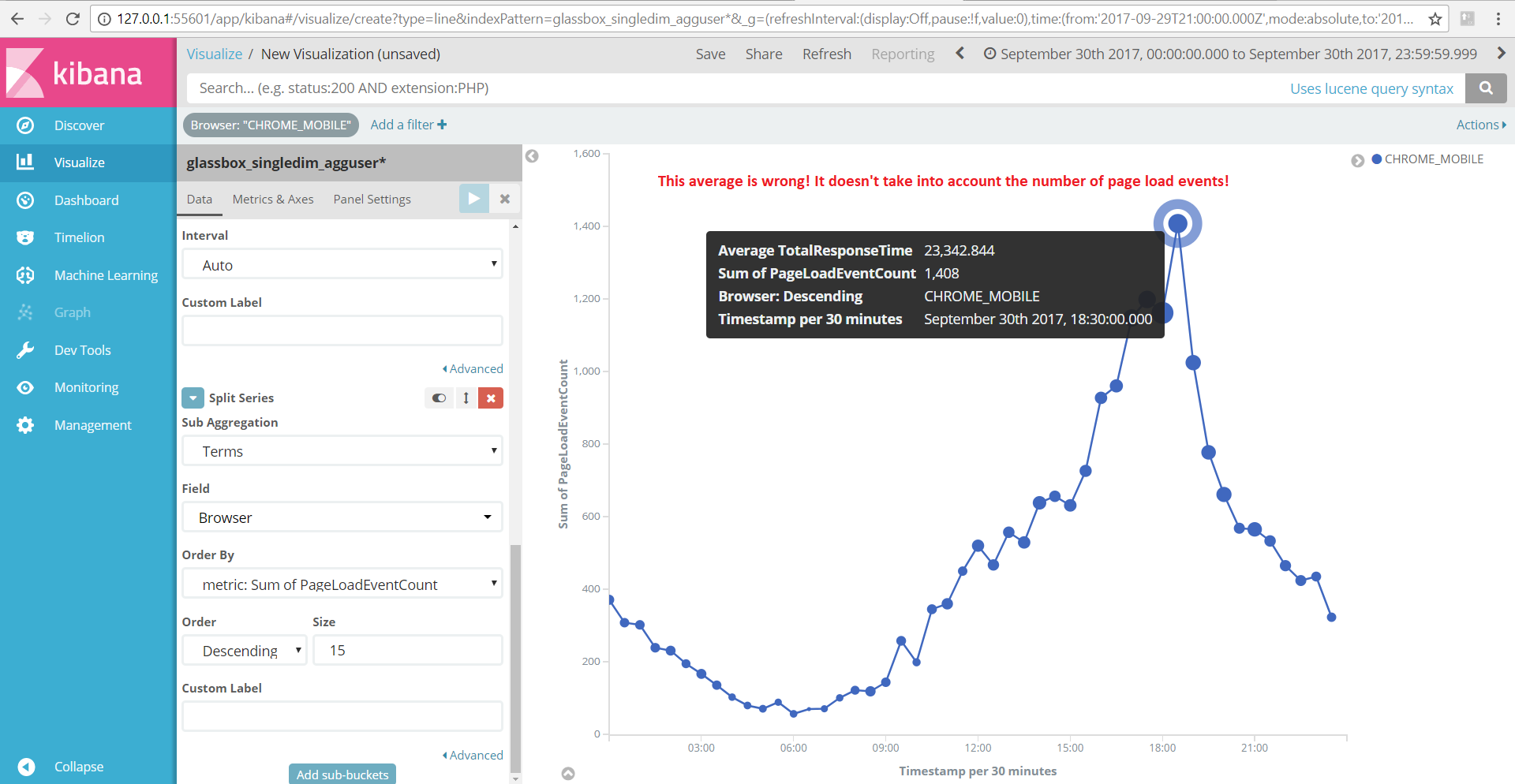

Am I missing something here? Shouldn't the high_mean detector take the summary_count_field_name into account when calculating an average?
Also, will the anomaly's probability be weighted according to how many events took part in the data which generated the anomaly? If not, the anomalies will be very susceptible to outliers when traffic is low.
Thanks