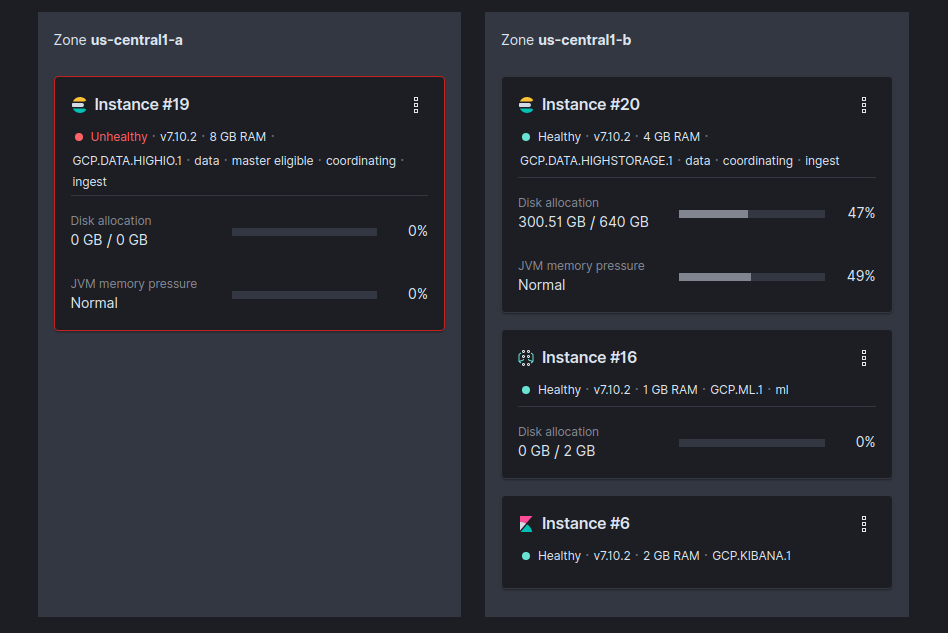
This is on a cluster on cloud.elastic.co
After reducing memory form the master node, I'm unable to get it back running. Logs show:
master_not_discovered_exception
Tried to reapply the last successful configuration, but it doesn't work, keeps showing the same exception.
Another weird thing is that the new instance show 0/0 on storage
Fair enough. We don't have access to the backend stuff that the Support team does, so it's hard for us to troubleshoot given what you are/aren't seeing sorry to say
Also, I can't access snapshots. Is there a way to force recreating the master instance?
The data instance looks fine.
Or is there a way I can create a new deployment using the data instance?
Am I missing something? Is ECE meant for non-production environments? Been down for 72 hours and still no response about the ticket I sent to support.
Is there some kind of additional fee for support? I don't see any upgrade option on Elastic Coud UI.
If you click on the three dots in the top right of instance you can force override its instance size back to 16GB (assuming there is capacity on the allocator - if not you may need to clear some), and then once it's back to life the plan should succeed
Can you DM me the support ticket id, I'll have a look at why you didn't hear anything back
Alex
(Incidentally needing >8GB on your master nodes is not that common and can be the sign that you are either oversharded or have a "mapping leak", it's worth looking into once you stabilize the cluster)
Apache, Apache Lucene, Apache Hadoop, Hadoop, HDFS and the yellow elephant
logo are trademarks of the
Apache Software Foundation
in the United States and/or other countries.