I am currently using an architecture with Elastic-Agent for log collection and Logstash for log forwarding. I am conducting stress testing to evaluate the hardware requirements and costs for my collector setup (Elastic-Agent + Logstash) using Apache JMeter to simulate EPS rates of 2000, 5000, and 10000.
The setup is as follows:
Apache JMeter (192.168.3.170) -> Elastic-Agent-[Custom UDP Logs] (192.168.3.172:515) -> Logstash (192.168.3.172:5044) -> Elasticsearch (192.168.3.173:9200).
My current collector setup includes:
- 4 Core
- JVM Heap: 4GB
- Batch Size: 125
When simulating 2000 and 5000 EPS, the Logstash Monitoring curves are relatively stable, and the event drop rate does not fluctuate much. However, at 10000 EPS, the Logstash Monitoring curve becomes unstable, and there is significant event drop variation.
(1)2000EPS


(2)5000EPS


(3)10000EPS

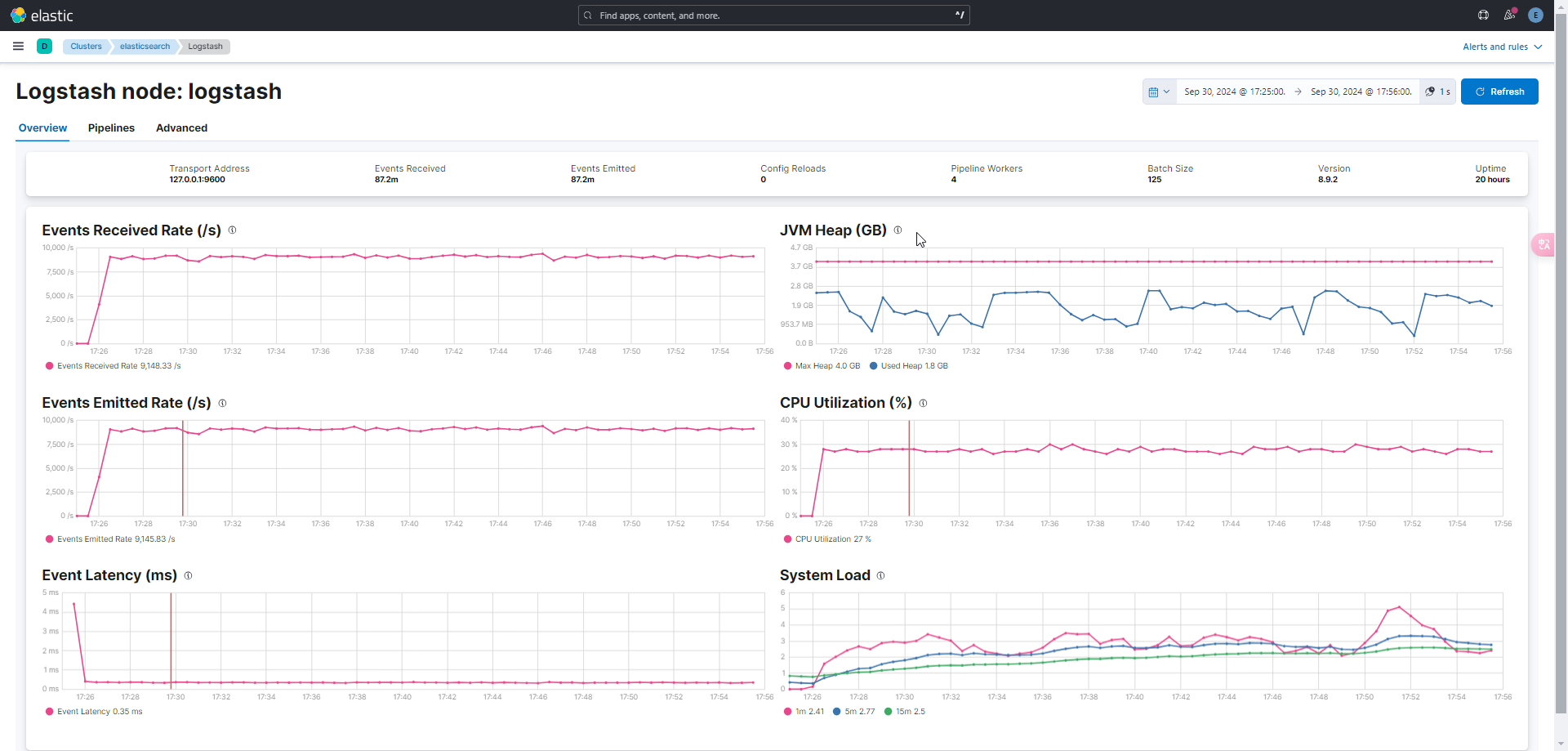
I am aware that the event reception rate of Logstash could be affected by factors such as Elasticsearch’s disk performance, shard configuration, and network.
I am looking for a more straightforward and effective way to quickly identify the cause of instability at 10000 EPS and evaluate the hardware requirements and costs for the Elastic-Agent + Logstash collector setup more accurately.
logstash-udp.conf
input {
elastic_agent {
port => 5044
ssl_enabled => true
ssl_certificate_authorities => ["/etc/logstash/certs/elasticsearch-ca.pem"]
ssl_certificate => "/etc/logstash/certs/logstash.crt"
ssl_key => "/etc/logstash/certs/logstash.pkcs8.key"
ssl_client_authentication => "required"
}
}output {
elasticsearch {
hosts => ["https://192.168.3.171:9200"]
data_stream => "true"
user => "elastic"
password => "password"
cacert => "/etc/logstash/certs/elasticsearch-ca.pem"
}
}