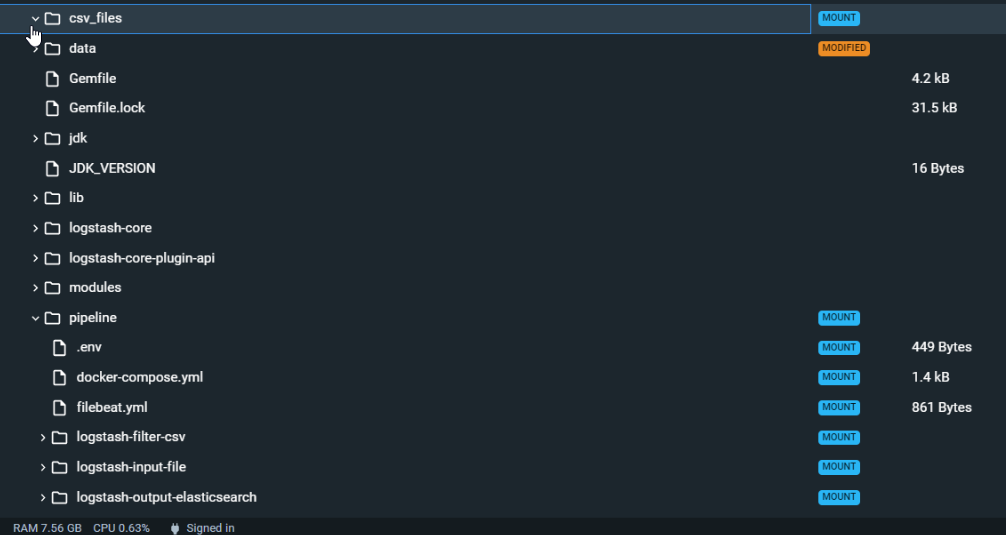
This is interesting. So I managed to retrieve the mapping and pipeline.json from the Import File approach.
I uploaded 1 csv file under integrations, Upload File.
mapping.json
{
"properties": {
"@timestamp": {
"type": "date"
},
"alarm": {
"type": "keyword"
},
"alarmvalue": {
"type": "long"
},
"description": {
"type": "text"
},
"equipment": {
"type": "keyword"
},
"eventtype": {
"type": "keyword"
},
"graphicelement": {
"type": "long"
},
"id": {
"type": "long"
},
"location": {
"type": "keyword"
},
"mmsstate": {
"type": "long"
},
"operator": {
"type": "keyword"
},
"severity": {
"type": "long"
},
"sourcetime": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss.SSS||yyyy-MM-dd HH:mm:ss.SS||yyyy-MM-dd HH:mm:ss||yyyy-MM-dd HH:mm:ss.S"
},
"state": {
"type": "long"
},
"subsystem": {
"type": "keyword"
},
"system": {
"type": "keyword"
},
"uniqueid": {
"type": "keyword"
},
"value": {
"type": "keyword"
},
"zone": {
"type": "long"
}
}
}
vs
{
"mappings": {
"properties": {
"@timestamp": {
"type": "date"
},
"@version": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"alarm": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"alarmvalue": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"column19": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"description": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"equipment": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"event": {
"properties": {
"original": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
},
"eventtype": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"graphicelement": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"host": {
"properties": {
"name": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
},
"id": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"location": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"log": {
"properties": {
"file": {
"properties": {
"path": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
}
}
},
"message": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"mmsstate": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"operator": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"severity": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"sourcetime": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"state": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"subsystem": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"system": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"uniqueid": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"value": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"zone": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
}
}
There are more fields mapped as long when I upload 1 csv.
When I ingest via pipeline, everything is keyword, "type": "keyword" even if entire column is a number.
ingest-pipeline
Not sure what I should look out for ingest-pipeline
{
"description": "Ingest pipeline created by text structure finder",
"processors": [
{
"csv": {
"field": "message",
"target_fields": [
"id",
"uniqueid",
"alarm",
"eventtype",
"system",
"subsystem",
"sourcetime",
"operator",
"alarmvalue",
"value",
"equipment",
"location",
"severity",
"description",
"state",
"mmsstate",
"zone",
"graphicelement"
],
"ignore_missing": false
}
},
{
"date": {
"field": "sourcetime",
"timezone": "{{ event.timezone }}",
"formats": [
"yyyy-MM-dd HH:mm:ss.SSS",
"yyyy-MM-dd HH:mm:ss.SS",
"yyyy-MM-dd HH:mm:ss",
"yyyy-MM-dd HH:mm:ss.S"
]
}
},
{
"convert": {
"field": "alarmvalue",
"type": "long",
"ignore_missing": true
}
},
{
"convert": {
"field": "graphicelement",
"type": "long",
"ignore_missing": true
}
},
{
"convert": {
"field": "id",
"type": "long",
"ignore_missing": true
}
},
{
"convert": {
"field": "mmsstate",
"type": "long",
"ignore_missing": true
}
},
{
"convert": {
"field": "severity",
"type": "long",
"ignore_missing": true
}
},
{
"convert": {
"field": "state",
"type": "long",
"ignore_missing": true
}
},
{
"convert": {
"field": "zone",
"type": "long",
"ignore_missing": true
}
},
{
"remove": {
"field": "message"
}
}
]
}