i have configured this rule but status always ok not active
what can i do to fix this

Check if the rule’s condition is actually being met — maybe there’s no data triggering it. Also, confirm the index pattern and time range are correct. Try simulating a matching event to test.

Hi @nzeland149
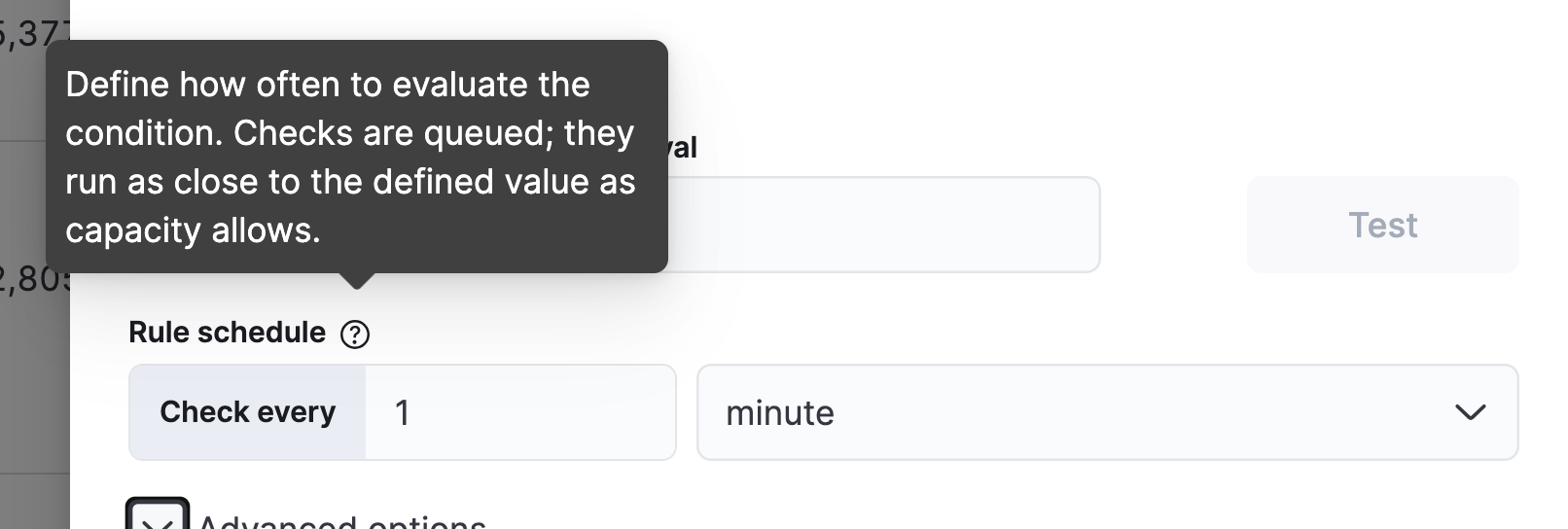
What is the rule schedule?
Also what that screen says is that the rule only detected 3 instances in the last 15 Days... so perhaps there has been no additional events.
Also you could try using a record score which is more granular.
Here is a bit of a comparison
Bucket Score
- Definition: The bucket score represents the overall anomaly score for a specific time interval or "bucket" of data.
- Purpose: It provides a high-level view of how anomalous the data is within that entire time period.
- Use Case: Useful for identifying time periods where there is a significant deviation from expected patterns. This can help in quickly pinpointing when anomalies occur over time.
Record Score
- Definition: The record score is a more granular score that represents the anomaly level of individual records or data points within a bucket.
- Purpose: It helps in identifying which specific records or data points are contributing to the overall anomaly detected in a bucket.
- Use Case: Useful for drilling down into specific anomalies to understand the underlying causes or characteristics of the anomaly.
Key Differences
- Granularity: Bucket scores are aggregated over a time period, while record scores focus on individual data points.
- Scope: Bucket scores give a summary of anomalies over time, whereas record scores provide detailed insights into specific anomalies.
Hello, thank you in advance.
I'm not sure what you mean by "rule schedule" — I configured the rule myself, and I'm working with buckets, not records, because my job is configured with 15-minute buckets.
When I switch to record and test the rule, it shows 0 anomalies.
I want to understand one thing:
Does the rule always stay in OK status until it detects an anomaly, then becomes active for 15 minutes, and if it doesn't detect anything afterward, it returns to OK?
Or how exactly does it work?
Sorry for the inconvenience.
First What version are you on? You screens look different.
The Rule Schedule is how often the Rule Runs...
Ahh apologies I was not clear on what were asking.... thanks for the detail.
Yes in general what you describe above is the intended behavior assuming that the in the next bucket the anomaly has recovered..
There are some minor caveats as it may stay active for longer than 15 minutes depending on your lookback window / how buckets to look back... if those are larger / longer that alert may stay active longer...
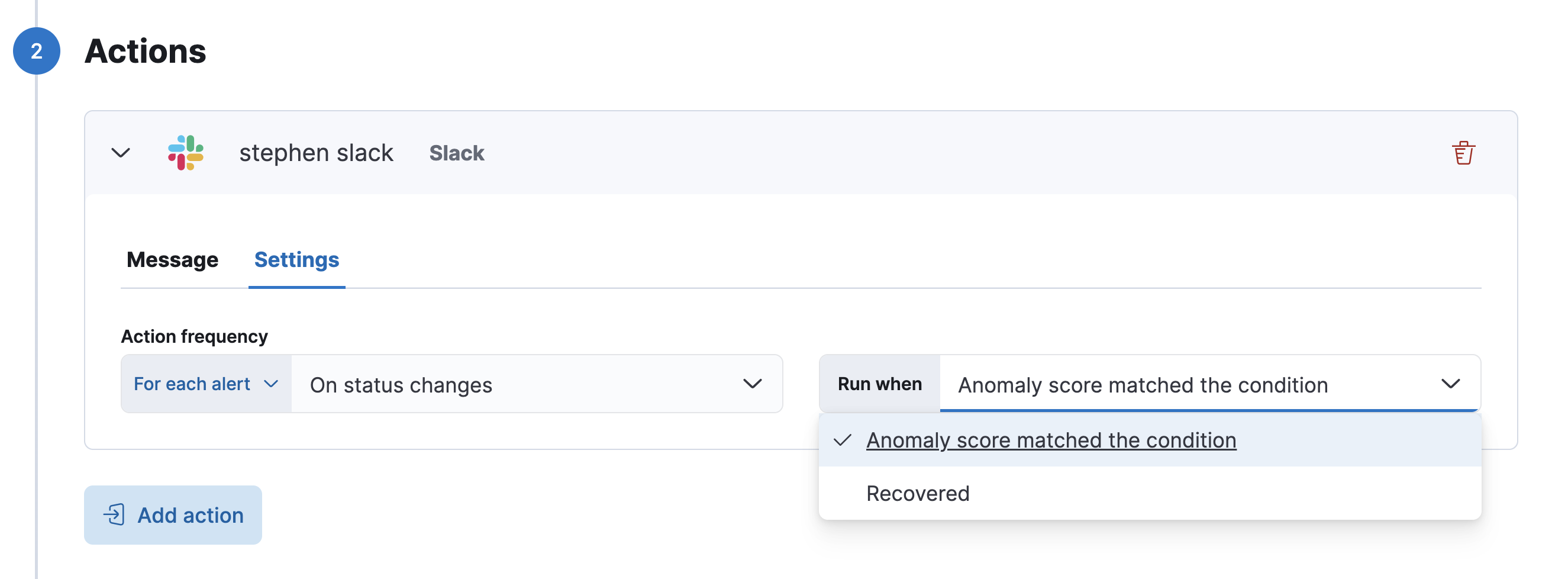
You can also send out an Recovered Alerts when the alert is recovered
However lets says you have this situation...
Anomaly detected 95 for bucket N
Anomaly detected 93 for Bucket N+1
Alert threshold >= 75

a) If you select Alert On Status Changes you will get 1 alert Avtive On Change ... it will stay active for the 2 buckets and the Recover.
b) Alert on Check Intervals you will get and Active Alert for Each Bucket
Hope that make sense.
im using the version 7.17.13
what is the prefeble for my use case
I just configured an smtp server as connector with the rule and its worked but my bucket is 15min and its longs 23min to recieve an email what if i reduced the bucket they may be some inconnvent
datafeed query is 60s and frequency 450s
I can not really answer that do you want 1 alert or 1 each time the rule runs, that is your call... me I prefer 1 alerts when the rule initially goes active.
Yeah that is a bit of an issue with Machine Learning jobs with alerts in General ... it can take a while.... they are not really the best for "instant" alerting.
If your ML bucket is 15 mins then the alert will not be generated until after the bucket is finished and then depend on the rule schedule... the data feed will not speed this up.
Why 23 minutes would need to dig into, you would need to share you complete config.
thanks a looot for u help
what config should i share
The Rule Config.... Also some delay may be via the Email system etc...

So the rule runs every minute... so you should get alerted about a minute after the bucket finishes processing. You did not show the lookback and other... settings... doubt they are an issue but when we ask for config usually it helps if you show the entire config..
Did you look at the alert details is the delay in the Email System?
you can see the entire alert details by putting {{.}} in the email it will be quite a bit of detail but you should be able to see when it is generated and then look for where your delay is
yes but even if there is no delay i will recieive notification after 15min
if i reduced the bucket what the negative i will get more false positive or high cpu usage or what and im sorry fot this lot of questions
This is tuning the job / result / alert ... I don't have an answer for you ... you need to test and iterate...
You can also take a look at this for tuning what is considered and alert.
I will say In General... Machine Learning + Alerts is not generally a great fit for "Race the Clock" alerting... if you are looking to be alerted within say 1-5 mins and ML job is probably not the right approach / great fit.
so what du u think i should use to be alerted
iam working with packetbeat logs do u have anyother suggestion
Can you clearly define the use case, because you might want to use another approach all together but I am not even clear on your use case.
Can you clearly define the use case? in detail?
Actually, even if bucket_span is something like 15m, you can still get alerted in a more timely manner if you consider that some detectors functions (like max, count, sum, etc) can determine that the bucket will be anomalous even before the bucket is finished and before all of the data has been seen*. You just need to ensure that the frequency parameter of the datafeed is a fraction of the bucket_span (it normally is).
The frequency parameter defines how often chunks of data within the bucket_span is fetched (and thus analyzed as partial results - denoted with a flag is_interim:true in the results index).
So, if you wanted to get alerted within 3-5 minutes of something anomalous you could simply make sure that for your job which had a 15 minute bucket_span, you set frequency equal to 5m and be sure to specify that you're looking for result_type:record and is_interim:true in your alert query.
* for example, if you're looking for a high value of something (like with max) and there's a value in the first batch that already is higher than expected - you don't need to wait until the rest of the data within the bucket to be processed, the system will mark this high value as anomalous but with the is_interim:true flag set. Alternatively, if you're using mean then you do need to wait for all of the data, because subsequent data could modify the overall average for the bucket_span
@richcollier Which frequency are you referring to the rule schedule or something else?
NM
frequency of the data feed, which is it...
in the first use case i am already using interim data but with bucket and i didnt get an alert but if i do record and i test my rule for the past anomalies i dont get nothing as anomali
what u mean by using mean i didnt understand this
and thankkks a lot man for all ur effort
yes my bucket is 15min and my frequency is 7.5min
why it should be a fraction