Hi there,
You gave me the hint to install x-pack and use the query profiler to analyze slow queries.
I gave it a try and now I am back with more questions; -)
ELK version is 5.1.2.
In visualization I see the following statistics:
Query Duration 2978ms
Request Duration 23691ms
Hits 941807
Index "tux-*"
Now I extracted the request:
{
"query": {
"bool": {
"must": [
{
"query_string": {
"query": "type: useractionlog AND NOT tags:processingTimeNull",
"analyze_wildcard": true
}
},
{
"match": {
"stage": {
"query": "Production",
"type": "phrase"
}
}
},
{
"query_string": {
"analyze_wildcard": true,
"query": "*"
}
},
{
"range": {
"@timestamp": {
"gte": 1492466400000,
"lte": 1492552799999,
"format": "epoch_millis"
}
}
}
],
"must_not": []
}
},
"size": 0,
"_source": {
"excludes": []
},
"aggs": {
"2": {
"terms": {
"field": "serviceCall.keyword",
"size": 20,
"order": {
"1": "desc"
}
},
"aggs": {
"1": {
"sum": {
"field": "processingTime"
}
}
}
}
}
}
When I put this complete request (including the aggregation part) in the profiler, I get following exception:
[aggregation_execution_exception] Invalid terms aggregation order path [1]. Terms buckets can only be sorted on a sub-aggregator path that is built out of zero or more single-bucket aggregations within the path and a final single-bucket or a metrics aggregation at the path end.
Why? Can I only analyze the query, oder also the aggregation?
If I delete aggregation part, and take only the query and size, I got following results:
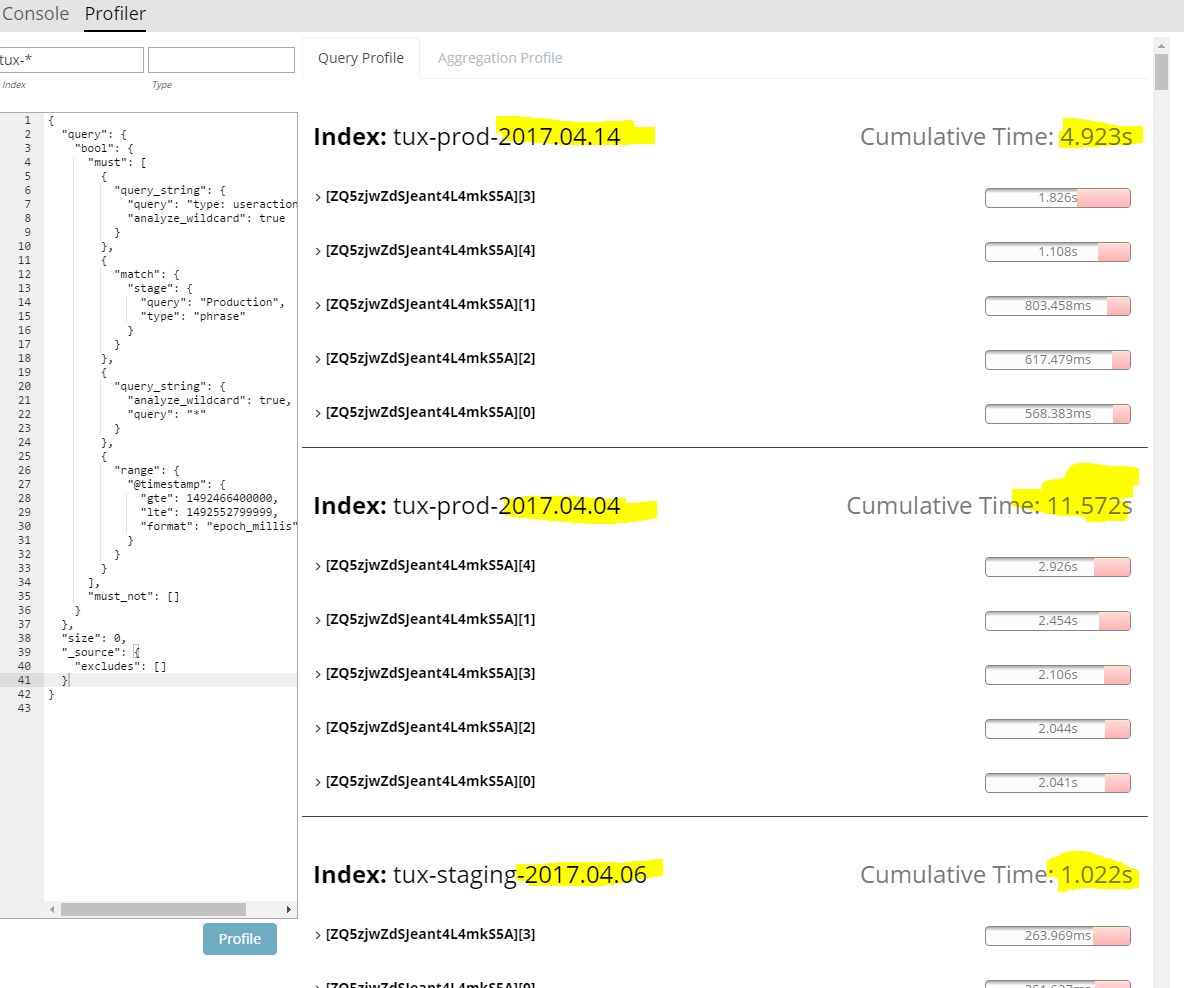

Now I have following questions:
-
requested timeframe is complete day of 2017-04-18 (CET). So why does querying an index which holds no data for that time interval take so long? As I understand Elasticsearch is smart enough to query only the needed indexes.
The index pattern is defined as followed:
-
Why is that query taking so long? Over a second for querying for a tag? Is filtering on tags slower than on fields und must be avoided?

Thanks a lot,
Andreas