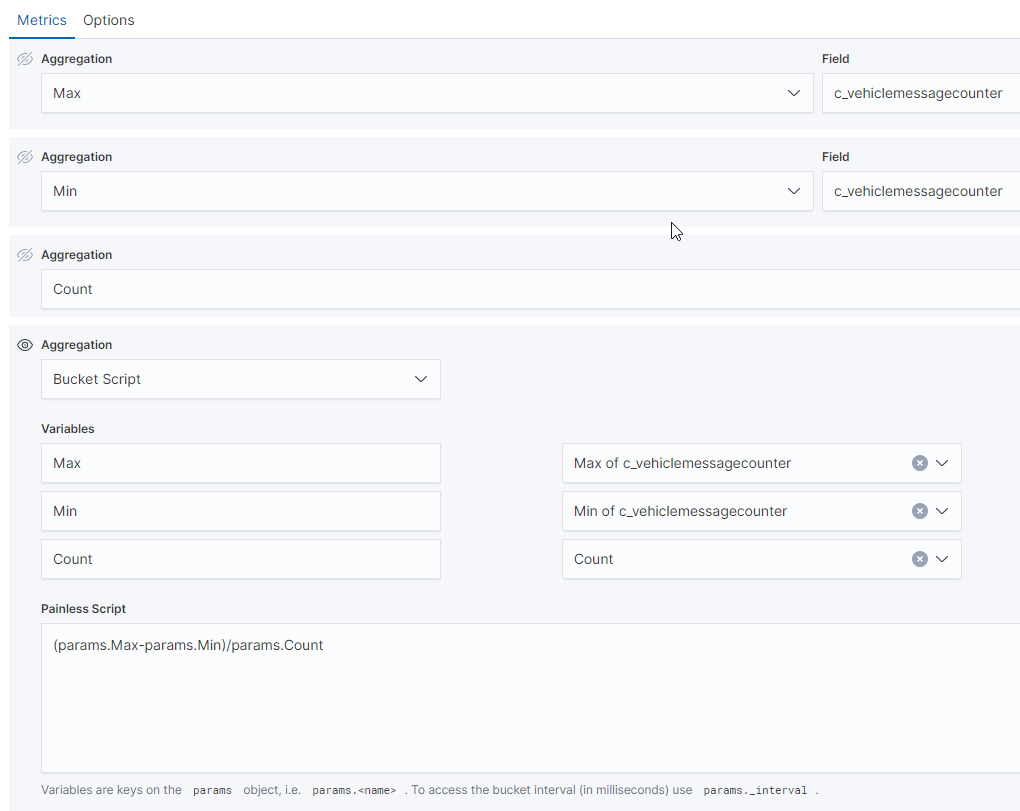
Thanks for your reply and sorry for being not clear. I try to clarify it:
I want to figure out how much messages are getting lost during transmission. Therefore I want to count the incoming messages (column COUNT) compared to the expected messages. Each message per transmission session (column Unique ID) has a ascendig counter value, so I can calculate the expected messages by Max Counter value - Min counter value = expected number of messages
The loss rate is then calculated by 1 - (Count / expected number of messages) = loss rate
In TSVB I want to visualize the loss rate over time for all Sessions, therefore I try to sum up all values for Count, Max and Min by each session. It should look like this then:
I see, unfortunately I think you can't configure such complex aggregations in TSVB. You should be able to get the individual metrics (Sum of Count, Sum of Max and Sum of Min) in the regular visualization types by using the "Sum Bucket" aggregation, but there you can't apply the formula afterwards...
Apache, Apache Lucene, Apache Hadoop, Hadoop, HDFS and the yellow elephant
logo are trademarks of the
Apache Software Foundation
in the United States and/or other countries.