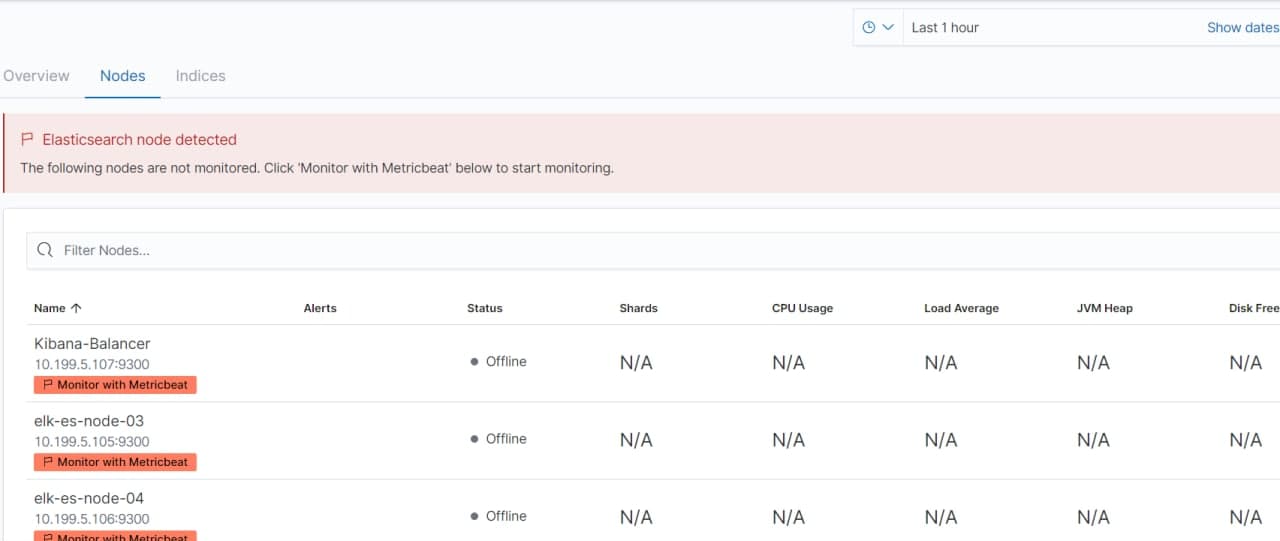
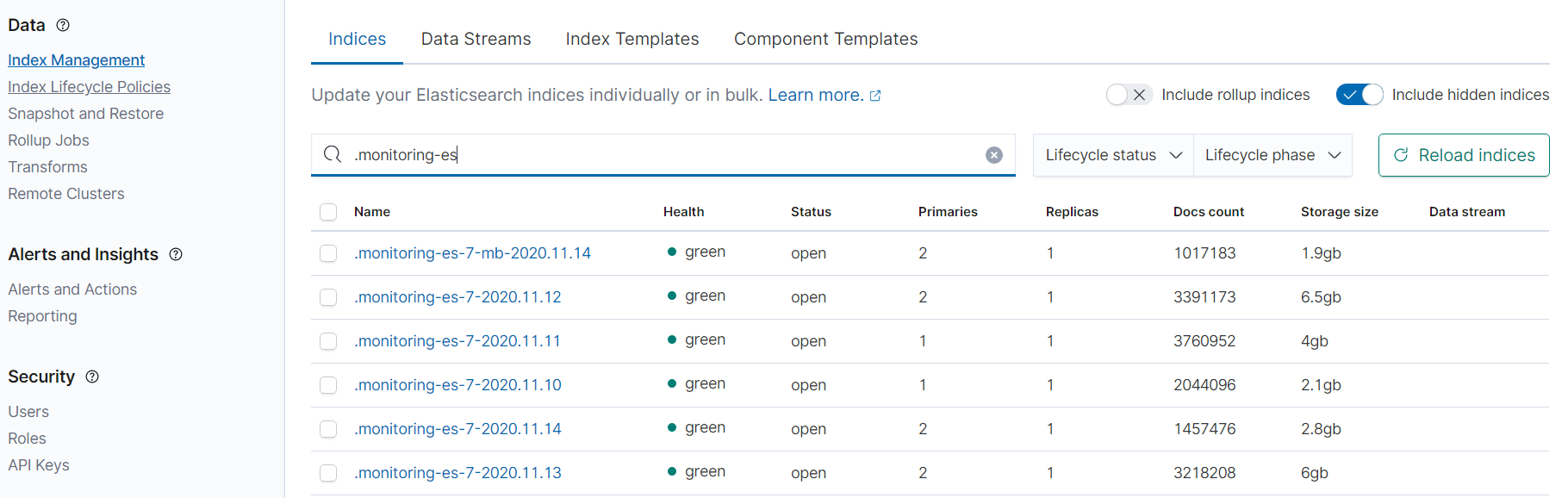
Sorry, forgot about one thing. A couple of months ago i've updated cluster from 7.1 to 7.9.1. Three days ago i noticed that old index lifecycle policices doesnt work anymore and created new ILM policy named [delete_old_indicies].
I tried
cat /var/log/elasticsearch/elk-cluster.mosgortrans.com.log | grep errors and there is nothing. cat /var/log/elasticsearch/elk-cluster.mosgortrans.com.log | grep monit show this
[2020-11-14T20:14:22,336][WARN ][o.e.x.i.IndexLifecycleRunner] [elk-es-node-03] current step [null] for index [.monitoring-kibana-7-2020.11.13] with policy [delete_old_indicies] is not recognized
[2020-11-14T20:14:22,361][WARN ][o.e.x.i.IndexLifecycleRunner] [elk-es-node-03] current step [null] for index [.monitoring-logstash-7-2020.11.13] with policy [delete_old_indicies] is not recognized
[2020-11-14T20:14:22,392][WARN ][o.e.x.i.IndexLifecycleRunner] [elk-es-node-03] current step [null] for index [.monitoring-es-7-2020.11.14] with policy [delete_old_indicies] is not recognized
[2020-11-14T20:14:22,424][WARN ][o.e.x.i.IndexLifecycleRunner] [elk-es-node-03] current step [null] for index [.monitoring-es-7-2020.11.12] with policy [delete_old_indicies] is not recognized
[2020-11-14T20:14:22,447][WARN ][o.e.x.i.IndexLifecycleRunner] [elk-es-node-03] current step [null] for index [.monitoring-kibana-7-2020.11.14] with policy [delete_old_indicies] is not recognized
[2020-11-14T20:14:22,461][WARN ][o.e.x.i.IndexLifecycleRunner] [elk-es-node-03] current step [null] for index [.monitoring-es-7-2020.11.13] with policy [delete_old_indicies] is not recognized
[2020-11-14T20:14:22,514][WARN ][o.e.x.i.IndexLifecycleRunner] [elk-es-node-03] current step [null] for index [.monitoring-beats-7-2020.11.14] with policy [delete_old_indicies] is not recognized
[2020-11-14T20:14:22,531][WARN ][o.e.x.i.IndexLifecycleRunner] [elk-es-node-03] current step [null] for index [.monitoring-es-7-mb-2020.11.14] with policy [delete_old_indicies] is not recognized
[2020-11-14T20:14:25,193][INFO ][o.e.i.s.IndexShard ] [elk-es-node-03] [.monitoring-logstash-7-2020.11.13][1] primary-replica resync completed with 0 operations
[2020-11-14T20:14:26,291][INFO ][o.e.i.s.IndexShard ] [elk-es-node-03] [.monitoring-es-7-2020.11.11][0] primary-replica resync completed with 0 operations
[2020-11-14T20:14:26,299][INFO ][o.e.i.s.IndexShard ] [elk-es-node-03] [.monitoring-es-7-2020.11.14][0] primary-replica resync completed with 0 operations
[2020-11-14T20:14:26,979][WARN ][o.e.a.b.TransportShardBulkAction] [elk-es-node-03] [[.monitoring-es-7-mb-2020.11.14][1]] failed to perform indices:data/write/bulk[s] on replica [.monitoring-es-7-mb-2020.11.14][1], node[IvxKqzsjRmCnOwJNqsLOQg], [R], s[STARTED], a[id=UnXFmesbR56lC-K-GBx66A]
[2020-11-14T20:14:27,386][WARN ][o.e.c.r.a.AllocationService] [elk-es-node-03] [.monitoring-es-7-mb-2020.11.14][0] marking unavailable shards as stale: [zE8Q1fIbQ2ag55TqVmgCTg]
[2020-11-14T20:14:27,386][WARN ][o.e.c.r.a.AllocationService] [elk-es-node-03] [.monitoring-es-7-mb-2020.11.14][1] marking unavailable shards as stale: [UnXFmesbR56lC-K-GBx66A]
[2020-11-14T20:14:27,730][WARN ][o.e.c.r.a.AllocationService] [elk-es-node-03] [.monitoring-kibana-7-2020.11.14][1] marking unavailable shards as stale: [Eb2VQq_jSYayqdSwtaNnJw]
[2020-11-14T20:14:29,801][WARN ][o.e.c.r.a.AllocationService] [elk-es-node-03] [.monitoring-beats-7-2020.11.14][1] marking unavailable shards as stale: [Dj8qZSUER2K9MT5hO6yibQ]
Apache, Apache Lucene, Apache Hadoop, Hadoop, HDFS and the yellow elephant
logo are trademarks of the
Apache Software Foundation
in the United States and/or other countries.