How does Kibana UI figures out that it has to scale up the interval if the query is going to results into too many buckets exception ?
Is it some fixed logic or it determines this by actually making a query to ES which would be inefficient IMO ?
Hi @S_Star
Which visualization are you referring to?
Generally, the bucket size is pre-calculated on the Kibana side before sending the request.
On some visualizations (depending on the version) you can influence the bucket size / number of buckets (like TSVB) and on newer versions on Discover...
What exactly are you trying to do or figure out?
Perhaps with a little more detail, we can help.
Example Discover now...

Just the regular example discover now, where if we select say time interval as second, you see a warning ...This interval creates too many buckets in the selected time rage....
Question is if its pre-calculated how does it do it ? Does it compute cardinality of fields etc ...
Specifically looking at how Kibana does it ?
Show the example please.
But in short date histogram buckets ...
Total Time / Time Interval = Number of Buckets
The query does not look at the cardinality for Discover... and I do not think it does for other Viz as well.
The number of buckets has a limit so that the query and the visualization have reasonable sizes and response time.
Here I asked for 24 hours in 1 sec
24 Hours (86400 sec) / 1 Sec = 86400 Buckets which is too large
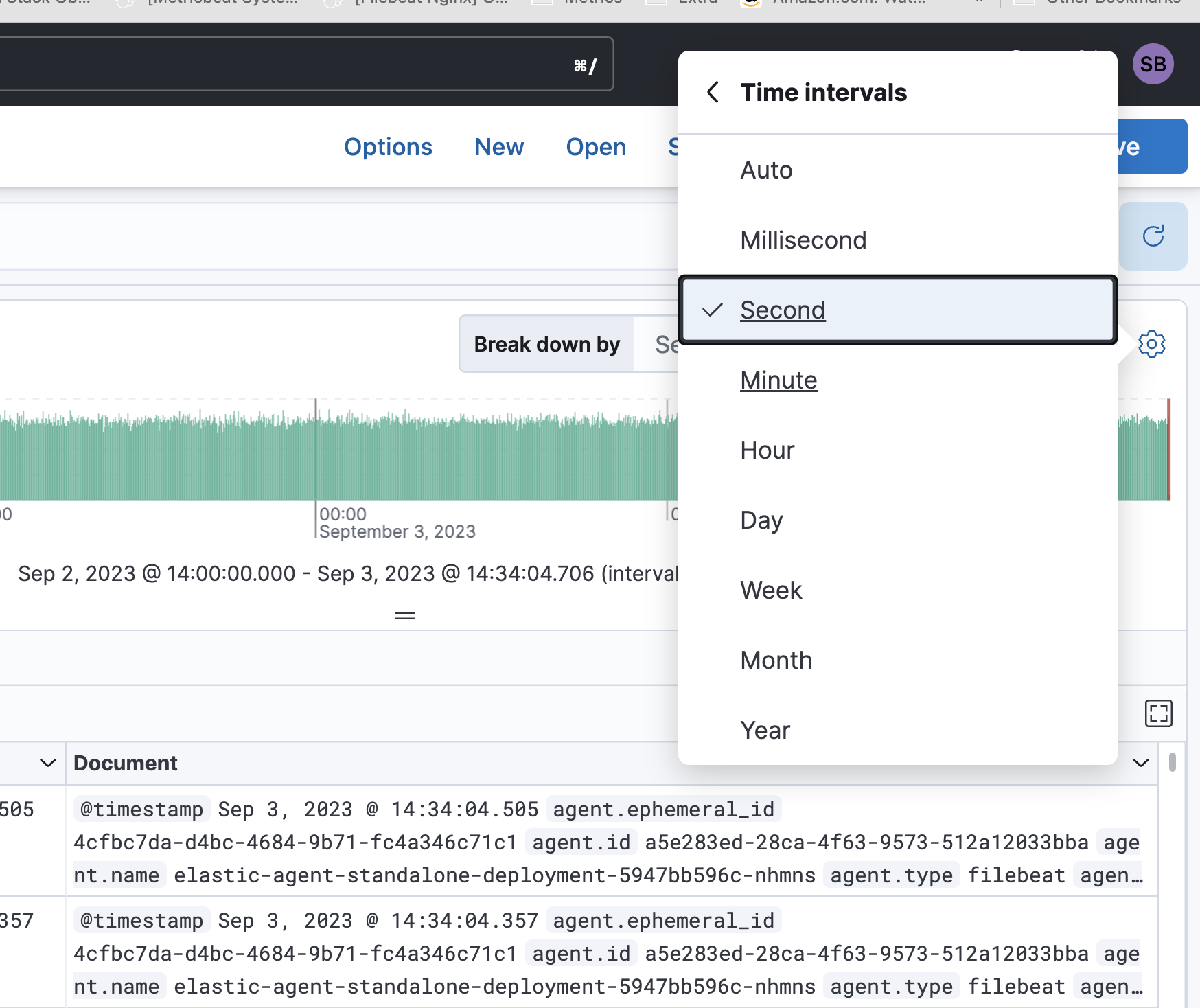

With 1 minute
24 Hours (1440 min) / 1 Min = 1440 Bukets work.


I do not know the exact size but I suspect it is either 1500 or 2000 buckets max or so...
But that is how it works as far as I know
You can look at the request as well there are actually 2 request 1 for the Graph (Data) and one from the Documents ... look at the Data One

So again what are you really trying to solve... or just curious?
Mostly curious ![]() but was also interested in doing something similar where we would want to stop an end user of our product to query data resulting into crazy number of buckets and was looking for some effective way to compute that upfront similar to Kibana. In our case, though its not just histogram, but any type of aggregations which can potentially result into explosion of buckets.
but was also interested in doing something similar where we would want to stop an end user of our product to query data resulting into crazy number of buckets and was looking for some effective way to compute that upfront similar to Kibana. In our case, though its not just histogram, but any type of aggregations which can potentially result into explosion of buckets.
I understand there are many server side default limits on ES which helps to prevent these explosion of buckets.