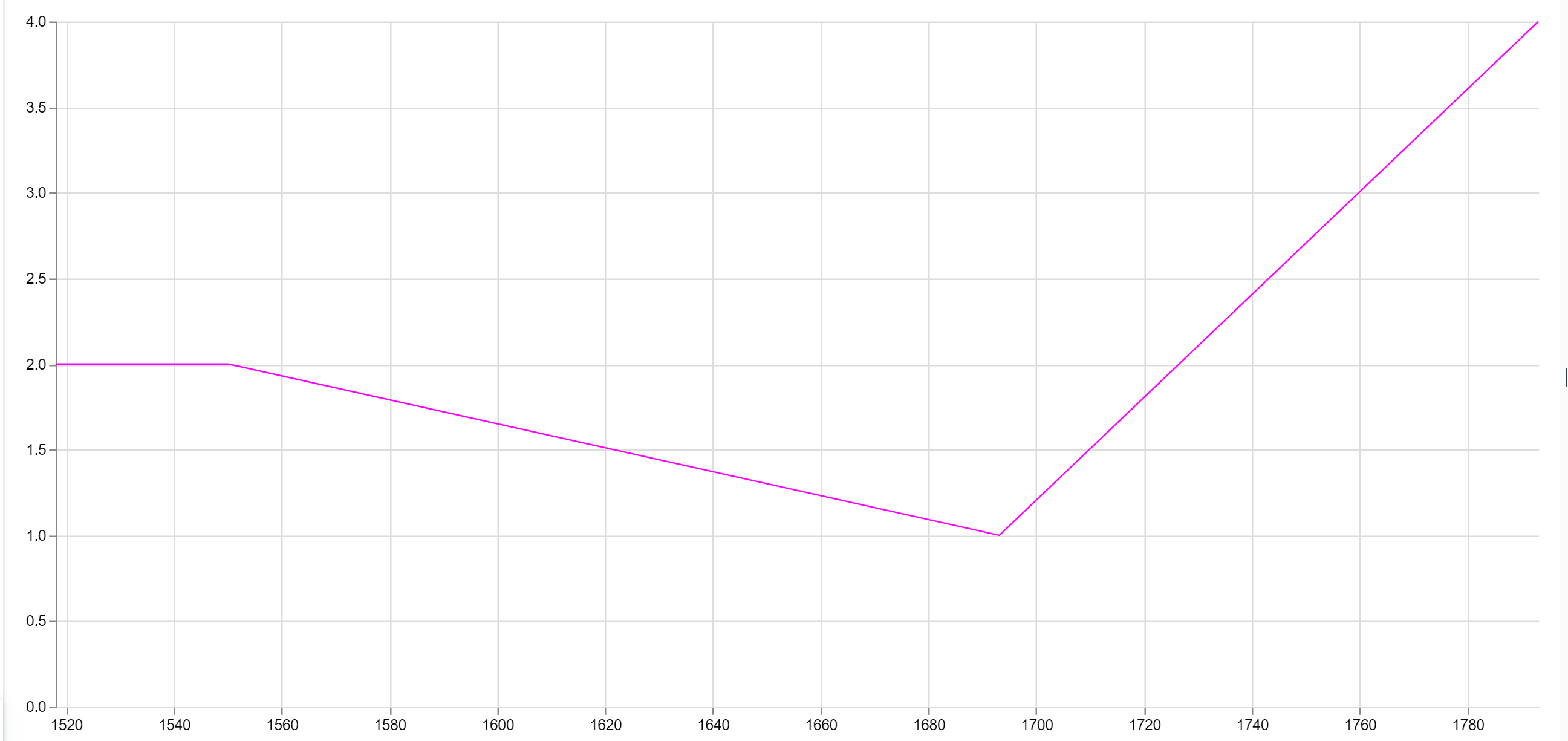
Hi Matthias,
Thanks a lot for your enthousiastic feedback.
First some explanations and then the sample data. I guess this explanation will be quite far from what you strictly need to analyze the problem, but maybe some background details on the usecase can help in some way ...
Historians often work with "archives" usually kept allong centuries in libraries, national or local archive centers or for example in churches which at that time had the role of the state for many things.
Those archives are simply old peaces of papers hard to read btw 
What historians would do is to "transcript" the contents of say several thousands of such archives relevant to their topic, and assign to each of them also some metadata (name of institution which produced or stores it, date of production, names of characters involved and/or referenced, or any other information interesting for the field of study (say amount and color of hats and shoes listed in an inventory).
From such data, often CSV or Excel file, produced by the historian, consistency and reconciliation work is usually needed, typically with a tool called "OpenRefine" (A regex-oriented Excel-like app to clean the data basically).
Then the (opensource) application I develop (metaindex.fr) intends to help historians (which are rarelly IT scientists) to define a catalog of their archives, customize it with proper fields and typing, populate, share, explore and present contents (and pictures, links etc.).
At last, Kibana is used as is then for the statistical part of the work.
This statistical work will very much change depending on the field of each historian and the type of the archives it work on, but basically it consists in correlating periods (for example histograms with 10-years-wide bars from year 1550 to 1710, or 3 pies charts showing evolution of avg amount of shoes in inventories depending on the social status of the owner, within 3 periods [1550,1600[, [1600,1650[ and [1650,1700[.
Well, that's it.
Following sample is extracted from validation data (so generated with a script). It contains french ids, sorry, but I tried to annotate it with some contextualisation.
Hope all of this can help. Feel free to ask for more details if needed, i'll be happy to provide more info or data!
Laurent
Sample Record
{
"_index" : "demo_archives",
"_type" : "_doc",
"_id" : "archive_0300",
"_score" : 1.0,
"_source" : {
// the date of production of the archive, used as Kibana timefield
"date" : "14/09/1534",
// where is stored the archive (an old church in this case)
"lieux_conservation" : "Abbaye de Fontenay",
// some local ID within the storage institution
"cote" : "ZTG 42//341",
// typology of archive (here somebody paying something to somebody else)
"type_acte" : "rente",
// ref to a picture of the document
"pic" : "document_0001.jpg",
// the type of institution who produced the archive at that time (here some kind of judge)
"type_producteur" : "judiciaire",
// coma-separated list of ids of some other documents in same index (i.e. links between archives referencing each other). This is interpreted by applicative layer but would be great to have support for interpreting such field in Kibana (the ELK 'relation' is quite restrictive for my use case). Dream would be abality to query over the properties of linked documents; single level of indirection would be already 98% of the need. Maybe i'll try to make a Kibana plugin to play with that one day.
"liens" : "archive_4262,archive_6380",
// id of user having performed last update (for applicative layer)
"mx_updated_userid" : 1344,
// date of latest modif of the document (for applicative layer)
"mx_updated_timestamp" : "2020-06-29 22:31:53.089"
}
The mapping
{
"demo_archives" : {
"aliases" : { },
"mappings" : {
"properties" : {
"cote" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword"
}
},
"fielddata" : true
},
"date" : {
"type" : "date",
"ignore_malformed" : true,
"null_value" : "0000",
"format" : "yyyy||MM/yy||MM-yy||MM/yyyy||MM-yyyy||yyyy/MM/dd||yyyy/MM||yyyy/MM/dd HH:mm||yyyy/MM/dd HH:mm:ss||yyyy/MM/dd HH:mm:ss.SSS||yyyy-MM-dd||yyyy-MM||yyyy-MM-dd HH:mm||yyyy-MM-dd HH:mm:ss||yyyy-MM-dd HH:mm:ss.SSS||dd-MM-yy||dd-MM-yyyy||dd-MM-yyyy HH:mm||dd-MM-yyyy HH:mm:ss||dd-MM-yyyy HH:mm:ss.SSS||dd/MM/yy||dd/MM/yyyy||dd/MM/yyyy HH:mm||dd/MM/yyyy HH:mm:ss||dd/MM/yyyy HH:mm:ss.SSS"
},
"liens" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword"
}
},
"fielddata" : true
},
"lieux_conservation" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword"
}
},
"fielddata" : true
},
"mx_updated_timestamp" : {
"type" : "date",
"ignore_malformed" : true,
"null_value" : "0000",
"format" : "yyyy||MM/yy||MM-yy||MM/yyyy||MM-yyyy||yyyy/MM/dd||yyyy/MM||yyyy/MM/dd HH:mm||yyyy/MM/dd HH:mm:ss||yyyy/MM/dd HH:mm:ss.SSS||yyyy-MM-dd||yyyy-MM||yyyy-MM-dd HH:mm||yyyy-MM-dd HH:mm:ss||yyyy-MM-dd HH:mm:ss.SSS||dd-MM-yy||dd-MM-yyyy||dd-MM-yyyy HH:mm||dd-MM-yyyy HH:mm:ss||dd-MM-yyyy HH:mm:ss.SSS||dd/MM/yy||dd/MM/yyyy||dd/MM/yyyy HH:mm||dd/MM/yyyy HH:mm:ss||dd/MM/yyyy HH:mm:ss.SSS"
},
"mx_updated_userid" : {
"type" : "short"
},
"pic" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword"
}
},
"fielddata" : true
},
"type_acte" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword"
}
},
"fielddata" : true
},
"type_producteur" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword"
}
},
"fielddata" : true
}
}
},
"settings" : {
"index" : {
"creation_date" : "1593469870363",
"number_of_shards" : "1",
"number_of_replicas" : "1",
"uuid" : "oNL5TFIiTU2S2TZJcSOtsw",
"version" : {
"created" : "7080099"
},
"provided_name" : "demo_archives"
}
}
}
}