I tried to open my CSV that i exported on Kibana Dashbord on Excel.
However it was broken like this. It looks BOM header issue. So I re-stored it file with "UTF-8 BOM" on Sublime Text.
But it is still broken. My OS is MAC. So i tried to save it on Windows Notepade. Then it is working, not broken.
I want to know that Kibana has a fixing plan this export CSV isssue?
Hi @Jungmi_Yoo, I tried to reproduce the issue but I'm not having success, I might need some more information from you.
What version of Kibana/Elasticsearch are you using?
Can you provide relevant steps to reproduce? A sample document or two that demonstrate the problem would be great.
What platform are you using Excel on? I don't have Excel, but I was able to import into Apple's Numbers without issue. Is Excel the only application that has issues with the file?
What version of Kibana/Elasticsearch are you using?
==> Kibana : 4.5.1 Elasticsearch : 2.3.3
Can you provide relevant steps to reproduce? A sample document or two that demonstrate the problem would be great.
==> reproduce steps
go to "Visualize"
select "Data table"
select "from a new search"
select my index
add bucket with these values.
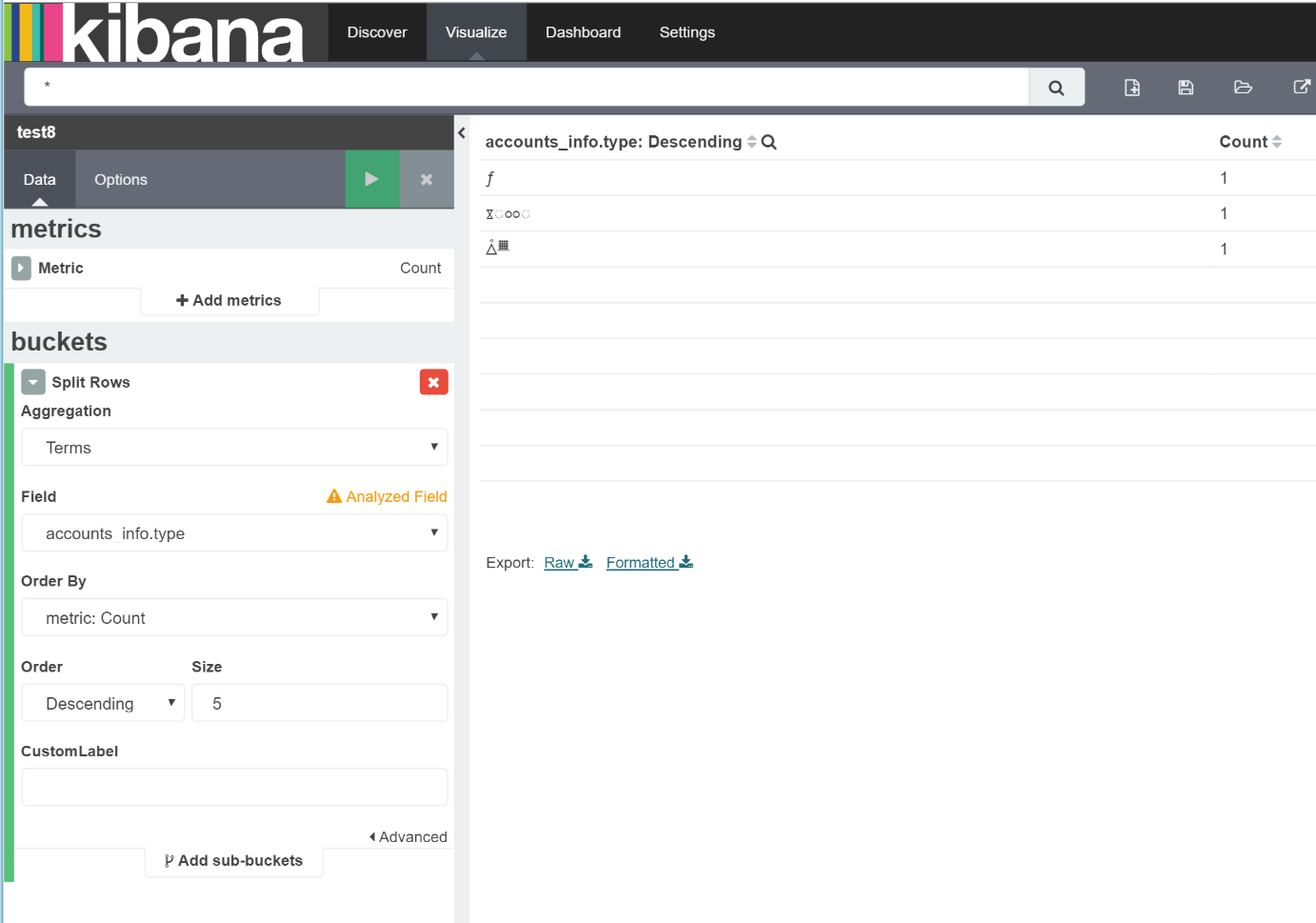
select "Split Rows"
Aggregation : "Terms"
Field : the filed has Korean text data.
order : Descending
run
export with "Raw" feature.
What platform are you using Excel on? I don't have Excel, but I was able to import into Apple's Numbers without issue. Is Excel the only application that has issues with the file?
==> this issue is raising on both platform MAC OS and Windows. when i opne the exported CSV file is fine. But this issue only produced when I open on EXCEL.
Therefore I'm thinking it looks BOM (Byte Order Mark) issue related with Microsoft.
After I loaded it I realized that the standard analyzer parsed that string on things it considered currency and maybe others into 3 separate terms. I'm not going to worry about that.
So here's what I have in my data table visualization;
If I just click on the csv file and select "Open with Excel" (Excel 2016) I get garbage;
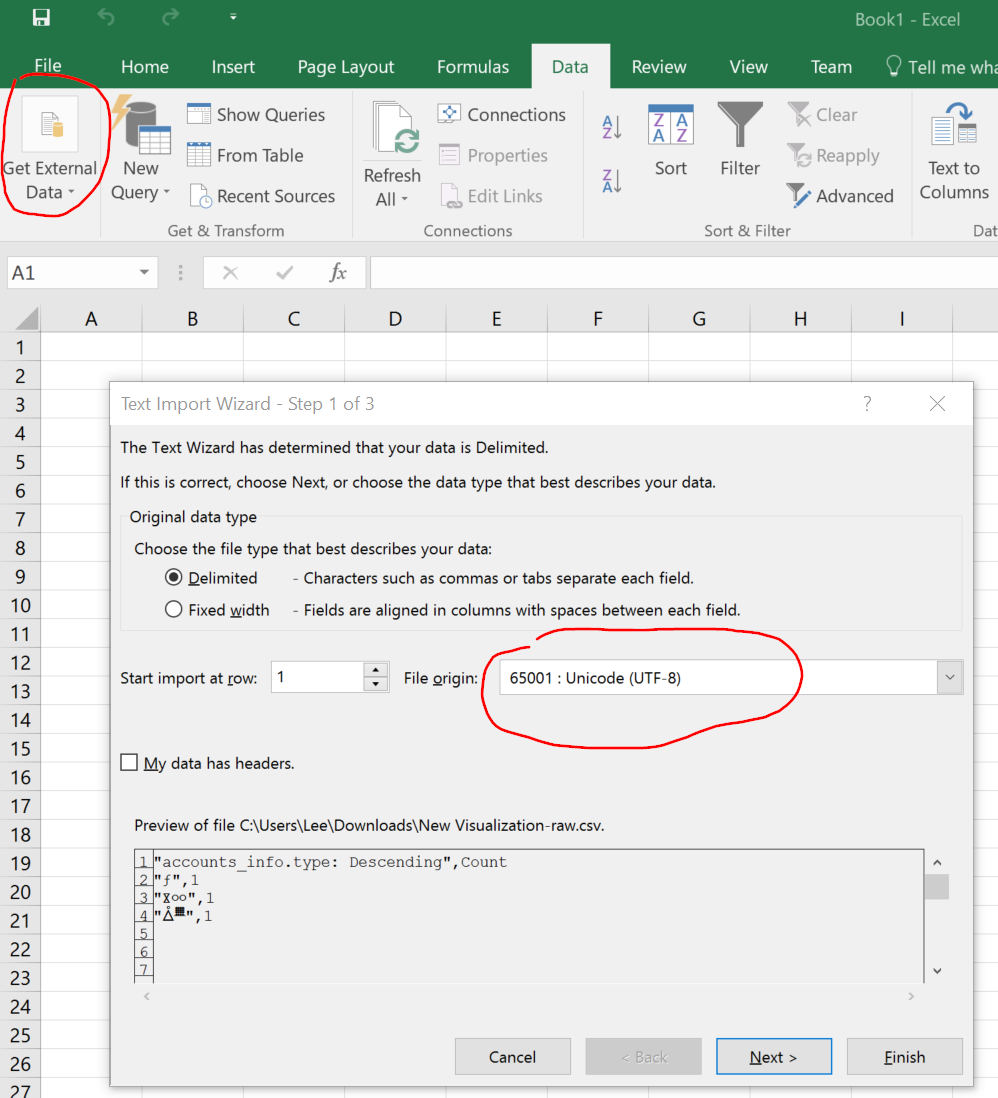
But if I open Excel and use Data > Get External Data > From File and check that the File origin is 65001: Unicode (UTF-8) (mine was already set that way).
Then I can see that the data is the same as I saw in Kibana (and the same as the document I loaded except for the analyzing);
So please try to load your csv into Excel by this Get External Data method and see if that works better.
Apache, Apache Lucene, Apache Hadoop, Hadoop, HDFS and the yellow elephant
logo are trademarks of the
Apache Software Foundation
in the United States and/or other countries.