I am using edge with Kibana and I notice as more documents have been loaded that I can refresh the webpage (using edge refresh button) and it can take up to 30-45s to load the page again. It never used to take this long.
The server is linuxmint pretty fully uptodate running in VMware workstation 17.5 with 4 CPUs and 32GB of RAM. The laptop features a 13700H with 96GB of RAM and 990 Pro SSDs. I was not expecting this slowdown so early on. I was wondering if anyone had any ideas on this ?
What I have done is load the following settings for JVM this afternoon:
and restarted elasticsearch. I was wondering if anyone has any ideas for performance improvement over and above what has been tried. It is probably too soon to know if these changes above are worthwhile but I’m thinking the use of the G1GC might be the main thing of benefit here.
So Im just doing some pie charts and graphs from the timeframe 22 Sep till now so will be retrieving date from the dmarc_aggregate-2025-09 (3k/1.4MB) and dmarc_aggregate-2025-10 (8k/2.4MB) indexes. The output is below:
If I click the edge refresh button (not the refresh in kibana) then this is where I can get the delay redrawing the screen. Its a custom dashboard with nothing too exceptional going on in my opinion:
Yes just loading Kibana dashboard I have created. Yes to document searching as there is an ES|QL query at top that selects a subset of the data and the tables also have columns that are not displayed but effectively filter the data I am interested in. Very basic however.
I will try firefox tomorrow for viewing and changing dashboard in Kibana and see how it goes. I just tried edge and firefox now and both are responsive. The delay was happening occasionally in edge (the 30-45s). Not all the time. When updates to the dmarc indexes happen it will typically be <10 docs added. The worst number of documents added to an index at one time would be 350 - small numbers.
Since you’re running a single node cluster many things will not go as planned.
Can you return cluster health api ?
The truth is it shouldnt matters for a small dataset like this, but let’s try to focus on potential overheads limits.
VM itself what is writing / using IO
How is the storage configured ?
Hardware SSD (AHCI, TRIM and guest OS config)
VM configuration
Virtualized System configuration
You should try to play with fio utility and check if you have abnormal values for SSDs i’ve ran countless lab clusters on 990s Pro and shouldnt be an issue
I'm still a bit confused whether you're saying that reloading the entire Kibana app is slow since you're running a refresh on edge..
Or you're saying when you refresh your dashboard it's slow..
The first is all about pulling down the whole kibana app, Not really my expertise
With chrome or Firefox you can open the dev tools and see what's taking the longest from the network and load and render perspective.
The second just refreshing the dashboard is about how long the queries take, which you can inspect the queries and see which ones are taking long and you could even put them in the profiler.
I have nothing specifically against those settings, but you also wrote:
without really providing any evidence? What makes you think this? Is there something in one of the gc.log files?
Generally I’d suggest to start with the OOTB settings, tune the heap sizes maybe, and only change other stuff based on experience or some specific evidence.
Also:
You can also set the dashboard to auto-refresh on a specific interval, or click the dashboards own refresh button?
Your elastic/kibana-running VM (they are both running in same VM?) is the only VM running on the laptop ? The laptop’s itself is doing anything interesting, aside from running Edge?
As well as other suggestions, when it’s slow, please try to get dump of the hot threads /_nodes/hot_threads if you can, via curl if necessary. And maybe snapshot of “top” output on both VM and host (or equivalent of top).
Of advice given, I’d do this first:
btw Edge has much the same thing too - Click the three dots → More Tools → Developer Tools.
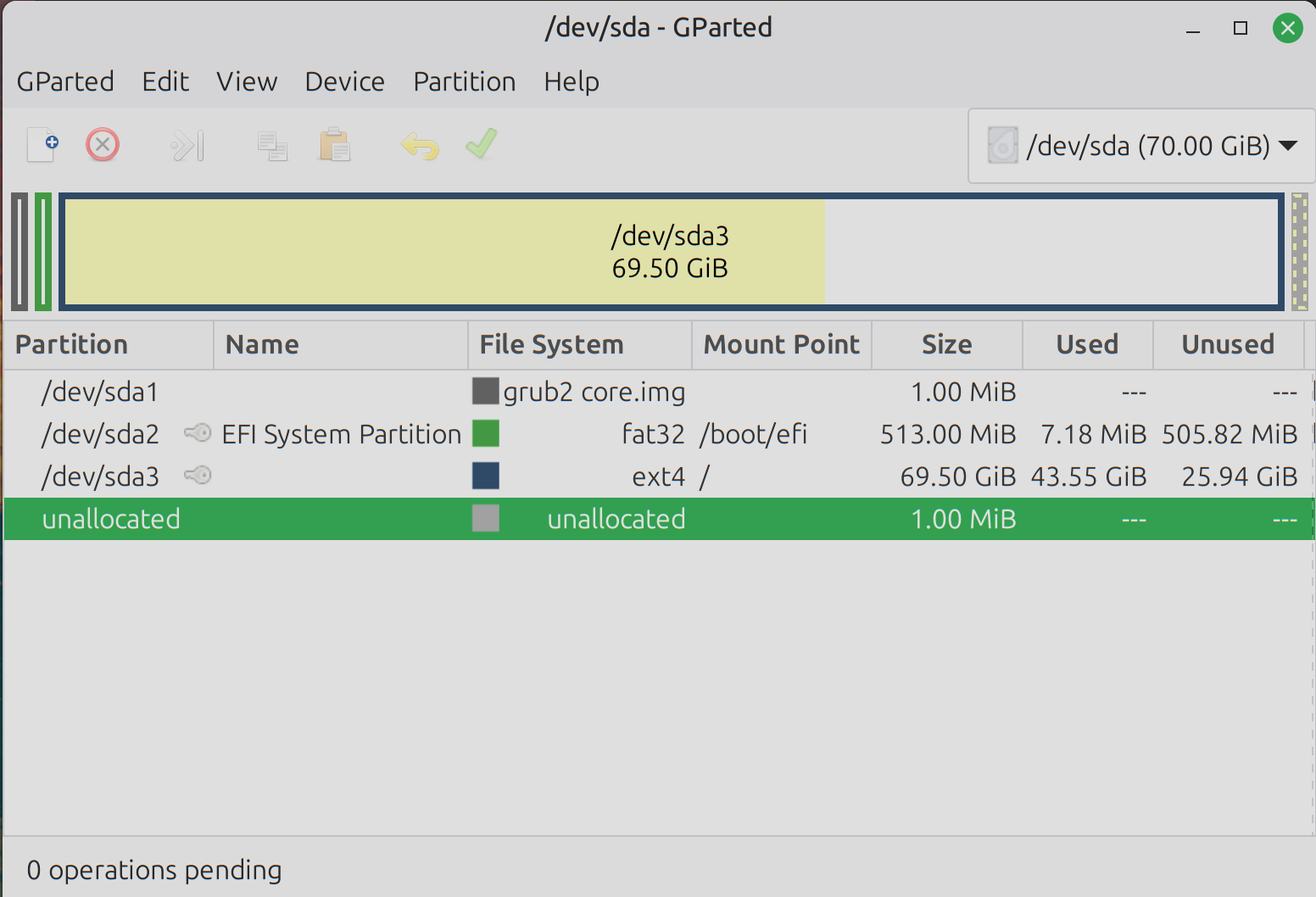
In passing, you might wish to set the 2 indices that seem to have an unallocated replica to have 0 replicas, a GET on _cat/indices should show you which, just to get cluster state to green.
Your elastic/kibana-running VM (they are both running in same VM?) is the only VM running on the laptop ? The laptop’s itself is doing anything interesting, aside from running Edge?
Yes elastic and kibana are running in the same VM. Only this one VM running on laptop and using the same laptop for MS Edge browser.
What I have done is moved the VM from my laptop to an Intel NUC and upgraded to V17.6.1 from V17.5 of VMware Workstation. Also changed the VM config to 8 processors (from 4) and left at 32GB RAM. Ever since I have done this using the edge refresh button to update the browser is consistently fast. Having said that, ever since the changes to the JVM config, whilst still running the VM on my laptop, I didn’t see the long delays in webpage refresh.
Anyway, on this Intel NUC (12th Gen), I have also setup metricbeat on the linux mint guest and this is reporting back to the same elastic DB. I figured with this metricbeat history I can perhaps do some more diagnosis if the issue rears its head again as metrics related to the garbage collection come through in the metricbeat data.
Apache, Apache Lucene, Apache Hadoop, Hadoop, HDFS and the yellow elephant
logo are trademarks of the
Apache Software Foundation
in the United States and/or other countries.