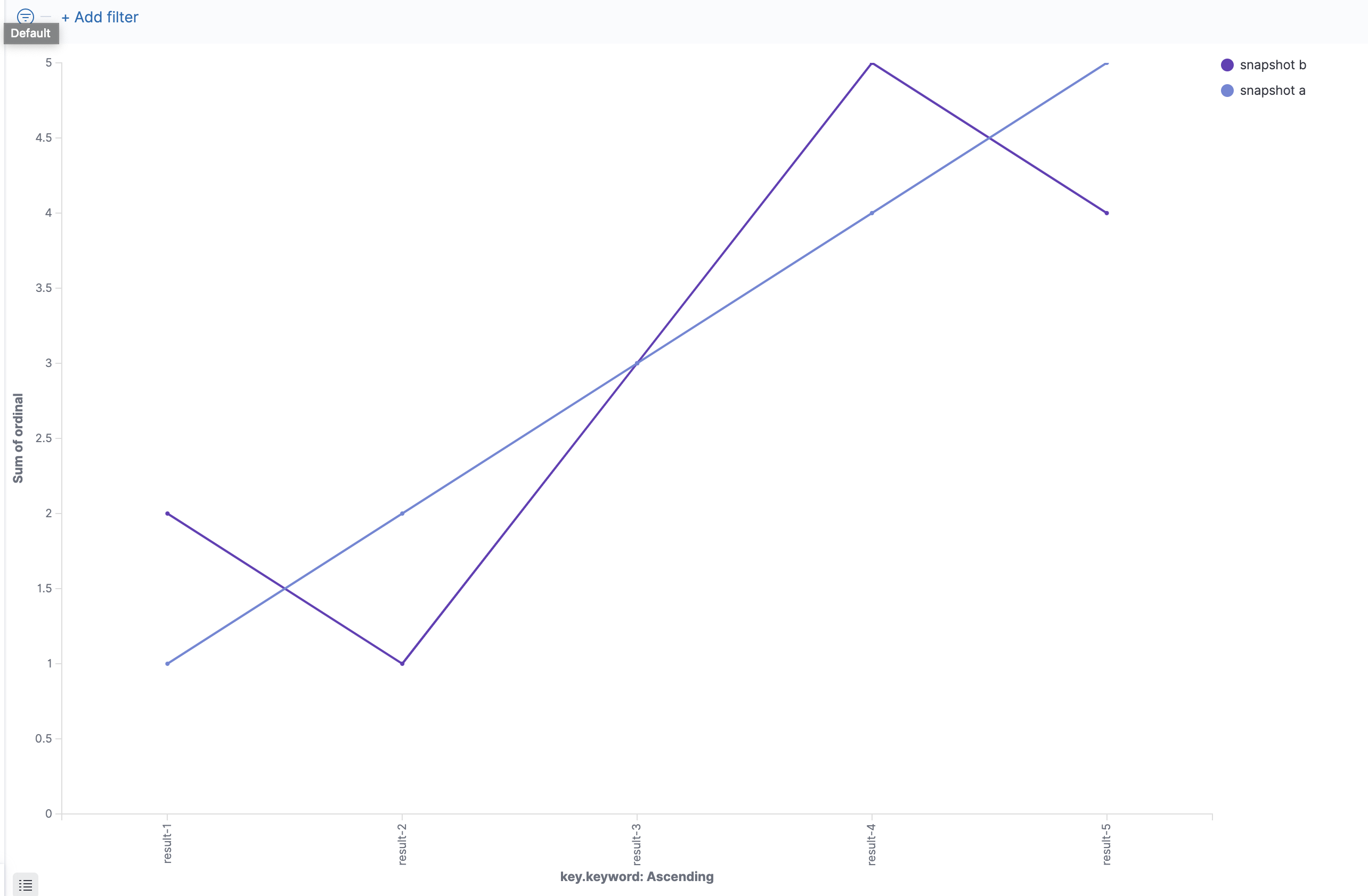
I am working on developing a visualization that, given two snapshots and a list of the top N results for each, create a line graph that compares the results for each snapshots .
Sample data:
PUT top-results
{
"mappings" : {
"properties" : {
"uri" : {
"type" : "keyword"
},
"ordinal" : {
"type" : "integer"
},
"snapshot" : {
"type" : "keyword"
}
}
}
}
Data:
PUT top-results
{"key":"hello","ordinal":0}
PUT top-results/_doc/1
{
"key":"result-1","ordinal":1,"snapshot":"snapshot a"
}
PUT top-results/_doc/2
{
"key":"result-2","ordinal":2,"snapshot":"snapshot a"
}
PUT top-results/_doc/3
{
"key":"result-3","ordinal":3,"snapshot":"snapshot a"
}
PUT top-results/_doc/4
{
"key":"result-4","ordinal":4,"snapshot":"snapshot a"
}
PUT top-results/_doc/5
{
"key":"result-5","ordinal":5,"snapshot":"snapshot a"
}
PUT top-results/_doc/6
{
"key":"result-2","ordinal":1,"snapshot":"snapshot b"
}
PUT top-results/_doc/7
{
"key":"result-1","ordinal":2,"snapshot":"snapshot b"
}
PUT top-results/_doc/8
{
"key":"result-3","ordinal":3,"snapshot":"snapshot b"
}
PUT top-results/_doc/9
{
"key":"result-5","ordinal":4,"snapshot":"snapshot b"
}
PUT top-results/_doc/10
{
"key":"result-4","ordinal":5,"snapshot":"snapshot b"
}
I would like for the X-axis to be ordered as such: result-1, result-2, result-3, result-4, result-5. This is derived by the 'key' values sorted by ordinal ascending but ONLY for values matching "snapshot a".
The Y-axis plots on the ordinal term. (There is only 1 result per bucket per snapshot, so the aggregation on this doesn't matter.) This means I am expecting a perfectly upward-sloping diagonal base line for "snapshot a" and a zigzagging line for "snapshot b" that still generally follows the upward trend of "snapshot a".
How can I go about doing this? I can create the perfectly diagonal line just fine by filtering the data to only use documents with the term "snapshot a", but then allowing "snapshot b" causes the desired sorting along the x-axis to mess up.
Can I accomplish this with JSON input as order by custom metric? This would seem the easiest approach -- filter the data used for creating the x-axis by only the terms with "snapshot a".
If not, what other approaches can I use to accomplish this? Transform into a new index?
We are using Kibana 7.4.0 .
Thanks!