Hi all, I haven't been able to find anyone else really doing this, and after a week of playing around I'm still pretty lost.
Currently my goal is to ingest vulnerability data into ELK, and then use Kibana to see the data, however the issue I am running into is that there is a lot of nested data, which I can't seem to extract and display.
One of the original solutions was to flatten the documents as much as possible, however due to the nature of vulnerability data, it result in too many documents, as each vulnerability has multiple updates, multiple affects products, and multiple external source links. Flattening the documents results in over 200 (sometimes way more) documents per one vulnerability;
- affected product 1, history 1, source 1
- affected product 1, history 1, source 2
- affected product 1, history 2, source 1
- affected product 1, history 2, source 2
When vulnerabilities affect 20+ products and have 20 updates, you can imagine how many documents would be created.
The best way I found to get around this was to nest the data, however this has caused problems of it's own, it seems that I am unable to use of the data in a 'nested' field in any visualisations.
The plan is to create a few different dashboards, one of them being a CVE Search function, where a user would enter a CVE and be returned with all the information, such as severity affected products, and a list of URLs, which is a problem as both of those have information stored in a nested field.
.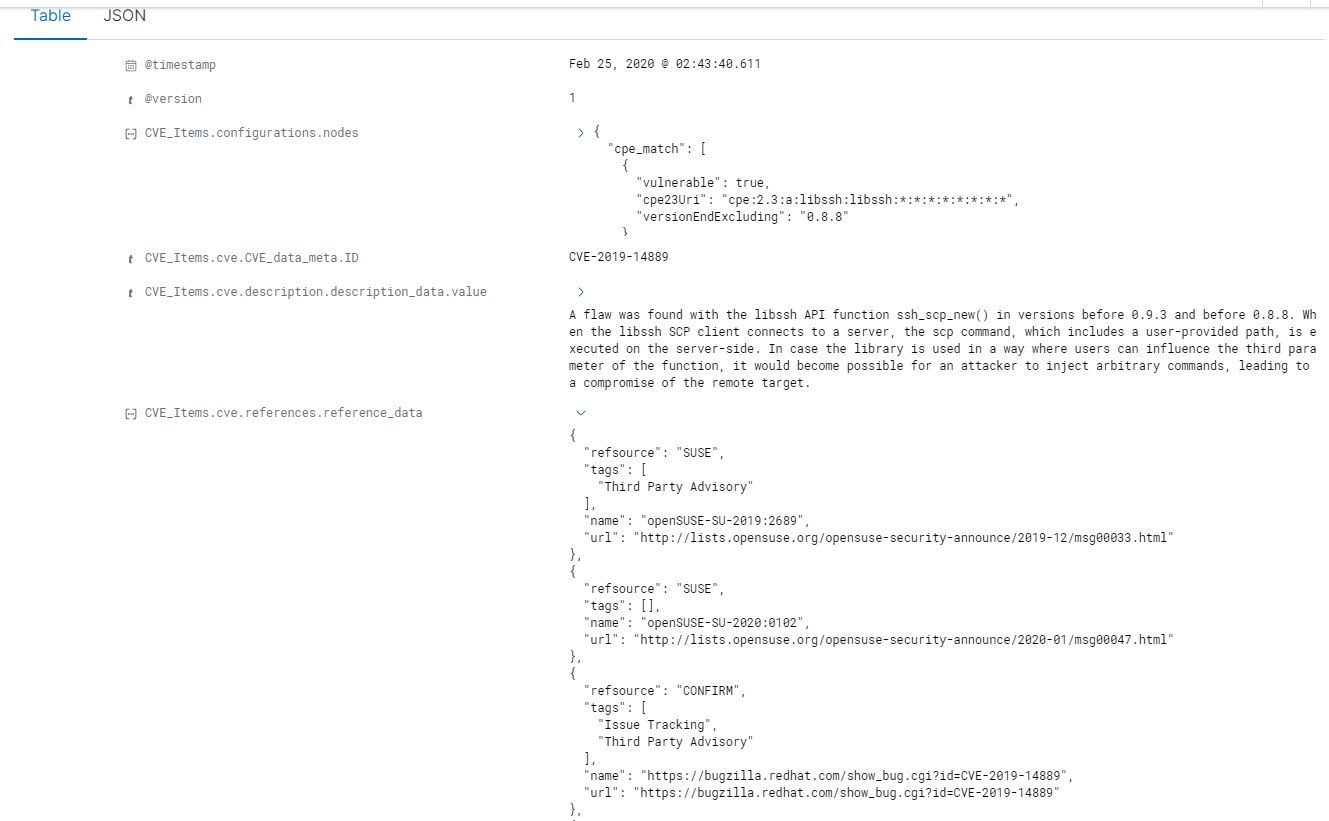
Pulling the CVE, and description is easy, the problem is getting the information in the references field, as it's been defined as a nested field.
I was wondering if anyone had any ideas on how I could go about this? It's starting to seem like ELK may not be the best place for this type of data.

